Event
Event Model
An event model can be created in Flowable Design by clicking the Create button and then selecting the Event entry in the Model Type drop down. The regular model creation popup is then shown where a model name and key can be set. An event model can also be created from a process or case model when selecting an event property in the property panel.
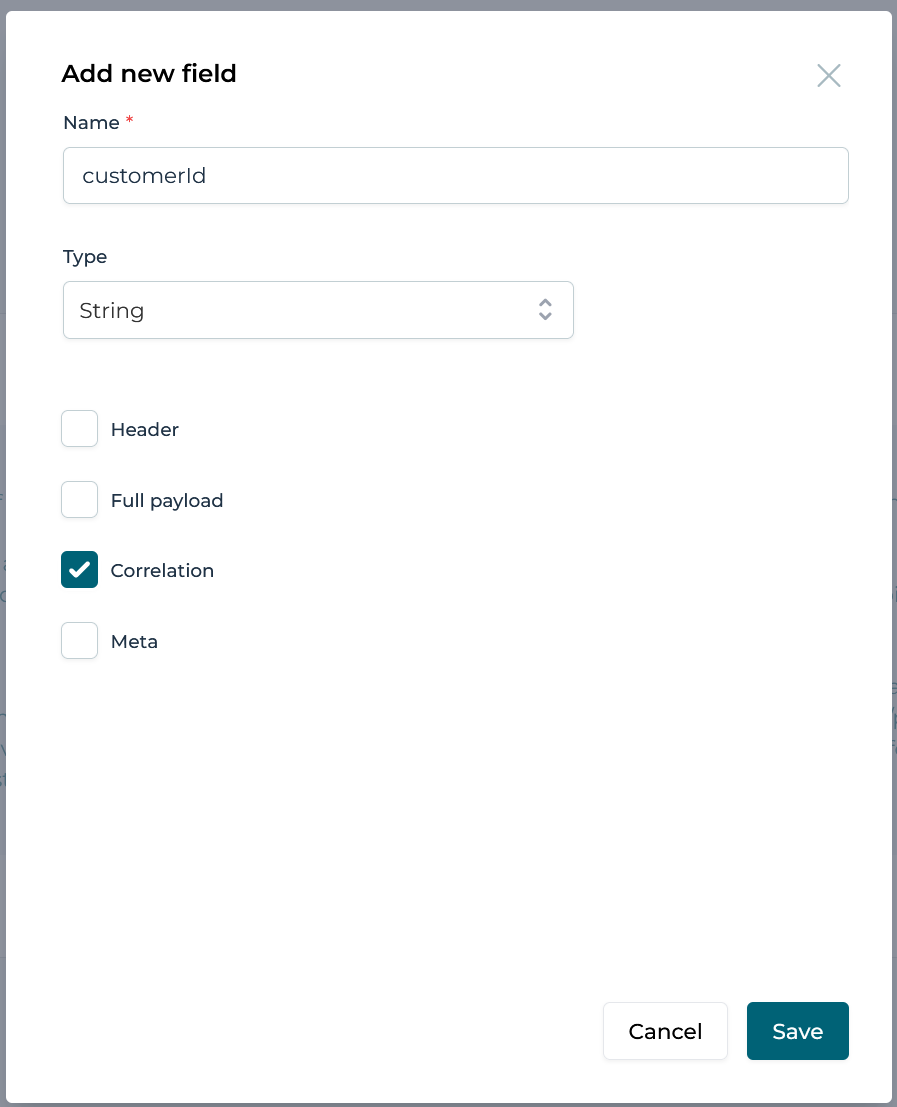
An event model consists of a number of fields, representing the data contained in the event. When creating a new event model, no fields exist and the Add field button must be clicked. It's now possible to provide a name and type for the field. We'll talk about the Correlation parameter and other flags later in this guide.
Note that we're not configuring how we get this field from the data that we receive. This is actually defined in the channel, that defines a step to extract the payload from the raw data and put it in the structure we're defining here.
When more fields are added, each field is shown as a row:

The icons in the Actions column allow to edit, remove, and move up or move down the field by holding and dragging the row.
Event Mapping
With the channel and event models having been discussed above, we've covered:
- How events are received from and sent out to the world outside of Flowable.
- How the data is mapped from the data (the mapping is defined in the channel) onto a data structure with a fixed structure (the fields of the event model).
There is one missing link to understand how this fits into a case or process model: event mapping. Let's look at the following simple process model:
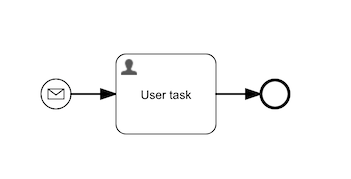
The idea here is that we want to start a new process instance whenever a certain event is received.
The start event here is an 'event registry start event' and allows choosing both an event and channel model:

When selecting an event model, a new property appears below that allows configuring the event mapping:

When clicking on this property, a popup is shown that looks like this:
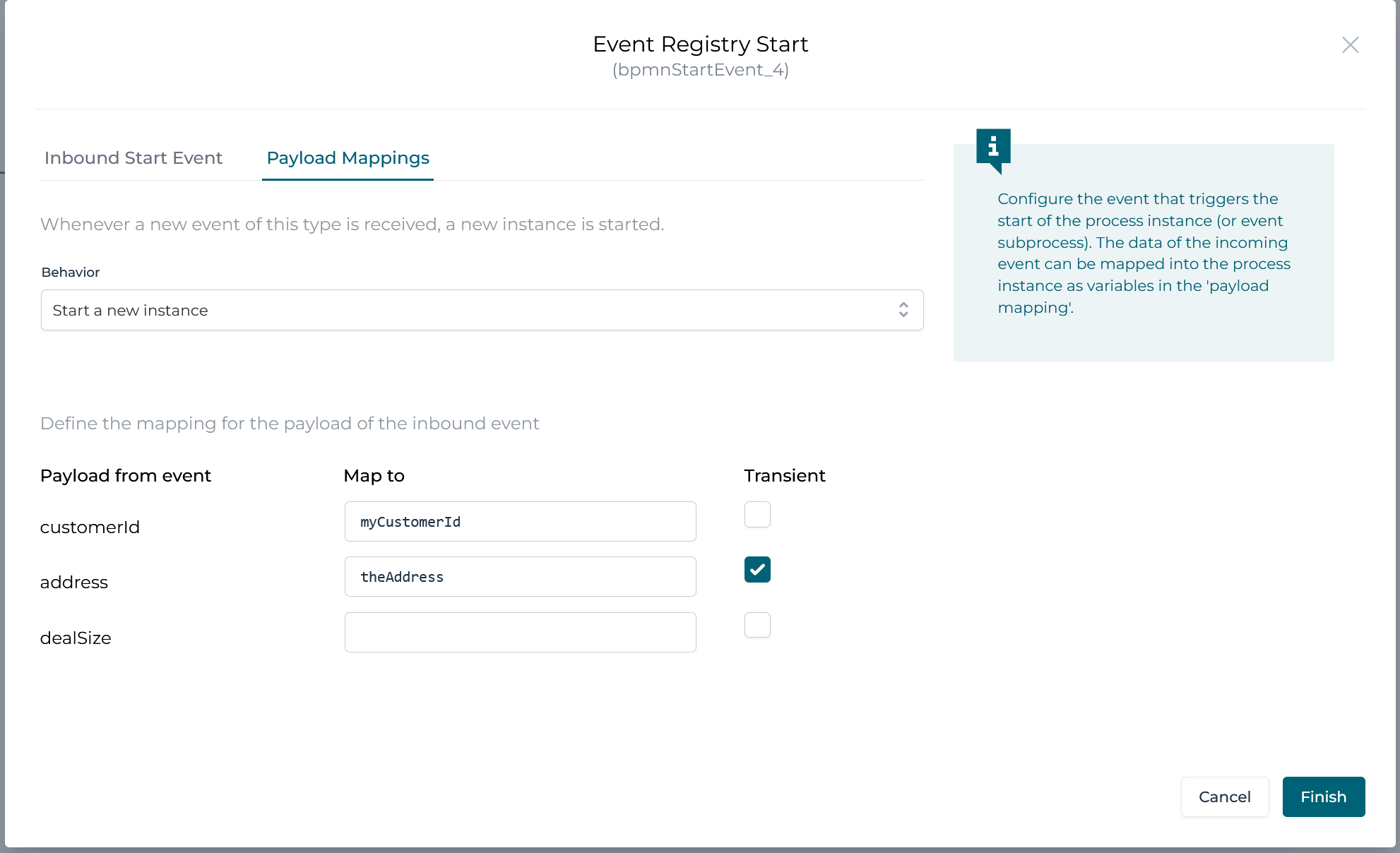
The fields defined in the event model are now shown here and the UI allows configuring how these event fields map to runtime process or case instance data.
 Summary
SummaryWhenever this event is received on the channel, a new process instance will be started (because the event type matches the type configured in the property panel). The data will have been processed in the pipeline and converted to the fields as configured in the event model. This way, the case or process modeler can now configure how this data needs to be used at runtime without having to know any of the technical details behind the (rather) complex technicalities behind the scene.
Correlation
An important concept when it comes to building process or case models with events is that of Correlation. In this context, correlation means how to relate the incoming event data to a running process or case instance. Let's look at a snippet of a case model to explain this.
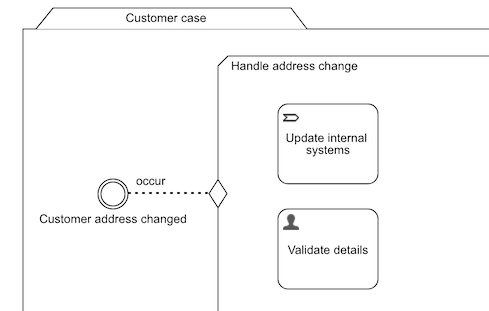
Every case instance based on this model will be waiting for a customer address changed event that then triggers a stage with multiple steps (in this example a process and user task are shown).
Let's make it a bit more explicit. Imagine that we have a Customer case for each of the customers our company has. Also imagine that the address change event originates from some sort of CRM system and that this systems puts events containing the customerId and the new address on a channel:
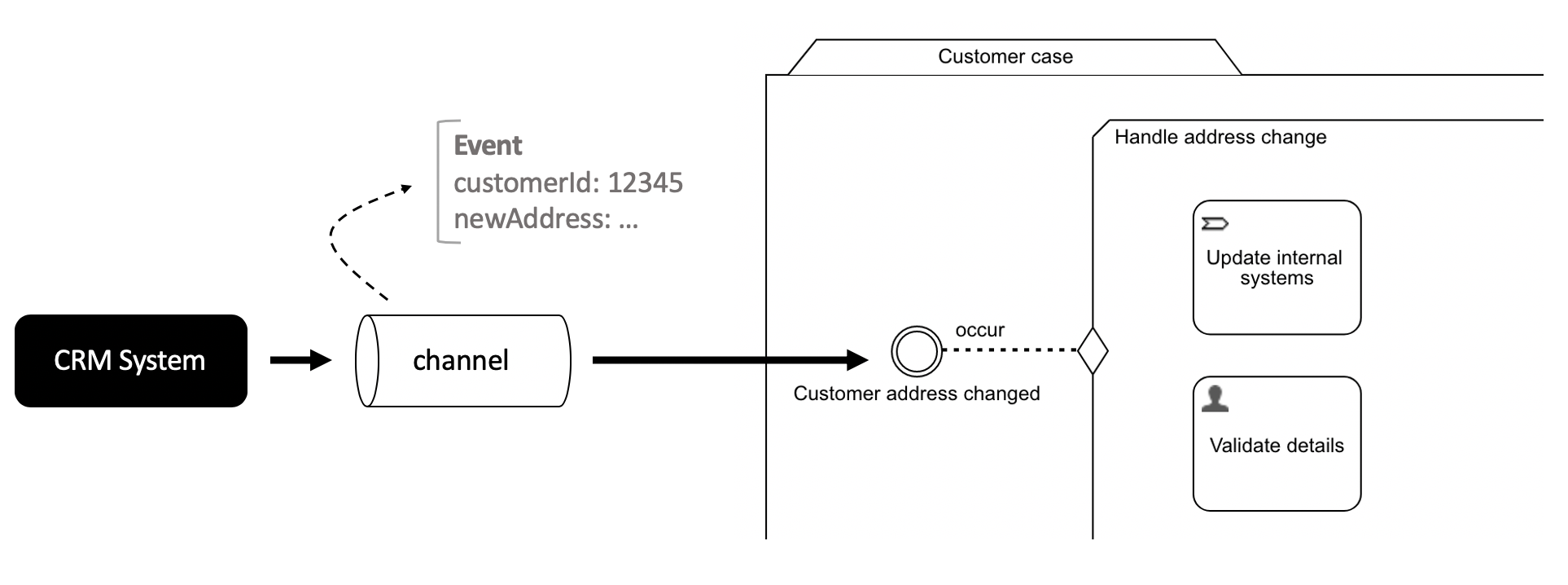
The question now is: how does Flowable know which instance exactly needs to be triggered? It would be extremely inefficient if all running instances would need to be checked for listening to a certain event. This is where correlation comes in.
In the event model section it was described that some fields can be marked as correlation parameters, in this example the customerId is marked as such:
When certain fields of an event model are marked as a correlation parameter, they are shown in a special way in the event mapping (section on top):
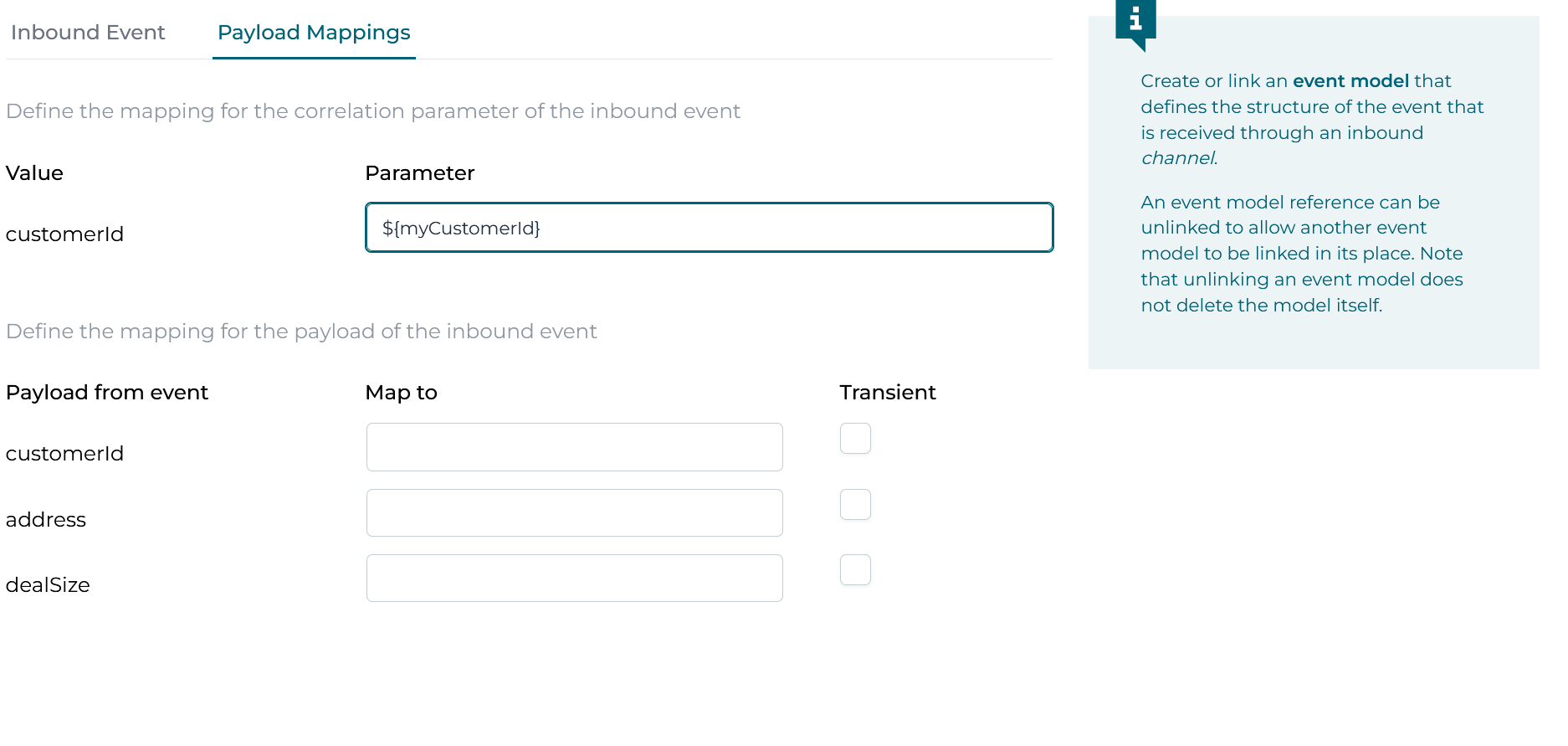
Suppose now that the Customer case has stored a variable named myCustomerId. As shown in the screenshot above, we've configured the event listener to listen for these customer address change events, but this particular instance is only receiving the event when the correlation parameter matches the value produced by ${myCustomerId}. If variable myCustomerId has value 12345 for example, we'll trigger the event listener for the case instance which has 12345 as value.
Note that an expression is used here, to resolve the variable. Without an expression, the matching would happen on the static text, being myCustomerId here, which is not wanted.
noteWithout getting too technical, let's describe what happens behind the scenes. When the Flowable engine encounters such a correlation parameter definition, it will generate a unique hash key based on all permutations of the correlation parameters (for this reason, it's wise to keep the number of correlation parameters limited to the minimum). When an event is received on a channel, a similar hash key calculation is made for the incoming event data, using the same correlation parameter definitions. Looking up which instance has which hash keys is very fast. This way Flowable passes the event to the relevant instance(s) in an efficient and scalable way.
Header, Full Payload and Meta
Besides the correlation flag, there are other flags on the event fields that can be checked. All of these are for advanced use cases.
For certain channel implementation, such as for example Kafka, JMS or RabbitMW, data can be passed in the body of the message or through headers of that message. If that's the case, the Header flag should be checked. At runtime, the event field value will be retrieved from the headers with the configured name instead of the body.
When the Full payload flag is checked, instead of mapping one particular field, all data will be mapped into this particular field. This makes this field effectively a copy of the full event data.
Lastly, the Meta flag marks the particular field as field that doesn't contain 'real' business data, but rather metadata.
For example, when using a Kafka channel it could be used to map the technical partition identifier to an event field.
In the advanced section of the Kafka channel, it could then be used as value for the Partition event field, which can be used for complex event distribution patterns across Flowable instances.