Inbound Channel
 Outdated documentation page
Outdated documentation pageThis is an old version of the documentation for Flowable until version 3.13 and for the Angular-based Flowable Design 3.14/3.15. If you are running the latest version of Flowable please check out the current version of this page.
A channel model can be created in Flowable Design by navigating to the Others section and then clicking on the Channel entry in the left-hand menu. The regular model creation popup is then shown where a model name and key can be set.
A channel model can also be created from a process or case model when selecting a channel property in the property panel of event-capable activities.
At the top of the page, the type of channel needs to be chosen: Inbound or Outbound. An inbound channel is used to receive events, while an outbound channel sends them out.
The inbound channel model UI look as follows:
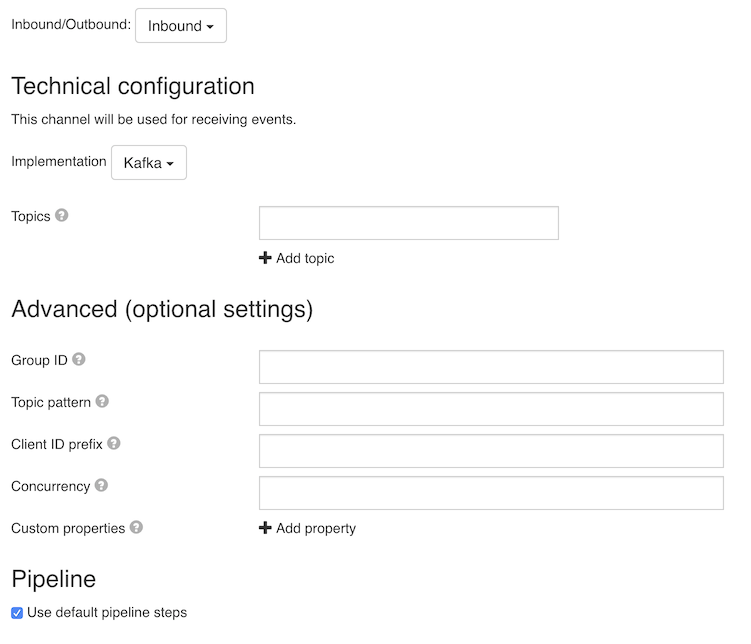
Depending on the channel implementation it contains different sections, described in the next subsections.
Kafka
Technical configuration
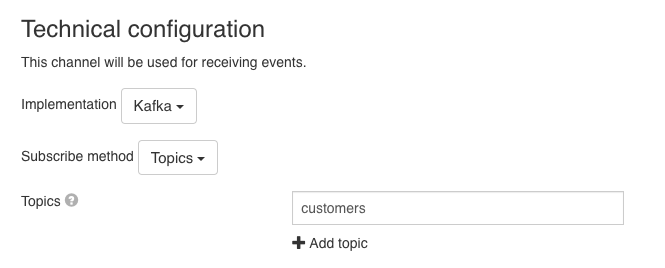
In this section the topics that the channel should consume need to be configured. It is possible to provide multiple topics that would be consumed. An expression can be used to determine the name of the topic that should be consumed.
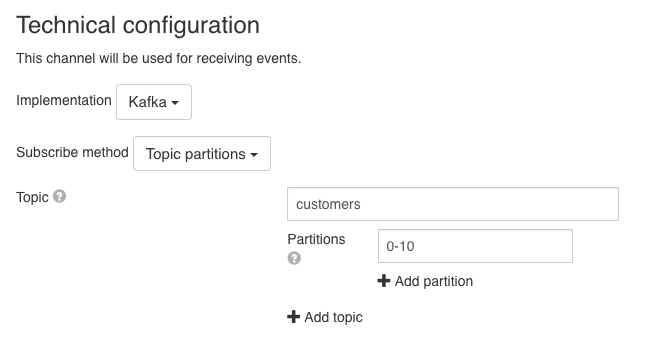
This is a more advanced option that allows to configure the topics and the particular partitions that should be consumed. The partitions that should be assigned to the consumer can be a string or an expression that resolves to a string. The string (or the resolved expression) can contain a comma-delimited list of partitions, or ranges of partitions (e.g. 0-5, 7, 10-15). e.g. in the configuration from the image the consumer is going to only consume events that are in partitions 0 to 10 in the customers topic.
Advanced configuration
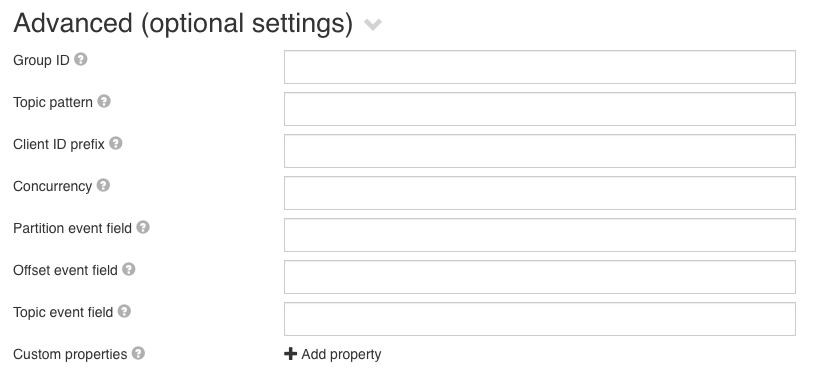
All options here are optional and allow using expressions. The available options are:
- Group ID - The identifier of the Consumer group that the Kafka consumer will be part of. By default, this is a combination of the channel key and tenant
- Client ID prefix - The prefix for the Kafka Consumer client id
- Concurrency - A numerical value or an expression resolving to a number, that is used to configure how many Kafka Consumers should be started.
- Partition event field - The name of the event field in which the partition on which the event was received needs to be written to
- Offset event field - The name of the event field in which the offset from the partition needs to be written to
- Topic event field - The name of the event field in which the topic on which the event was received needs to be written to
- Custom properties - A Kafka consumer can have many custom properties set. This can be used to configure those properties. e.g. this can be used to configure a custom value deserializer
Retry configuration
v3.12.0+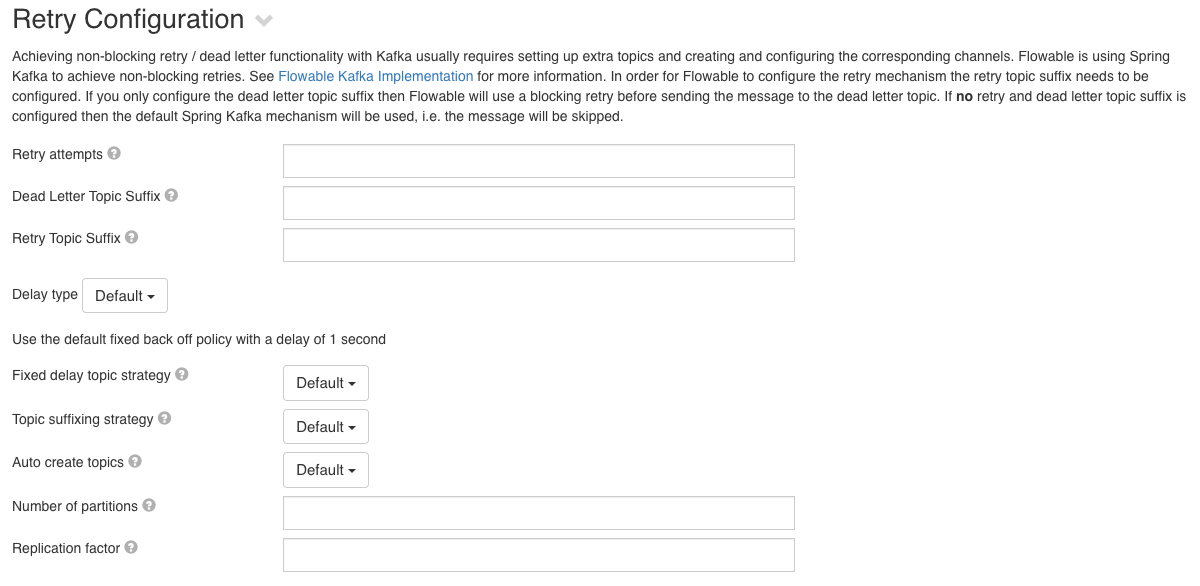
Achieving non-blocking retry / dead letter functionality with Kafka usually requires setting up extra topics and creating and configuring the corresponding channels. Flowable is using Spring Kafka to achieve non-blocking retries. See Spring Kafka Non-Blocking Retries for more information.
In order for Flowable to configure the retry mechanism the retry topic suffix needs to be configured. If you only configure the dead letter topic suffix then Flowable will use a blocking retry before sending the message to the dead letter topic. If no retry and dead letter topic suffix are configured then the default Spring Kafka mechanism will be used, i.e. the message will be skipped.
Flowable exposes the following properties (expressions are allowed for some of them)
- Retry attempts - The number of attempts made before the message is sent to the DLT. Expressions must resolve to an integer or a string that can be parsed as such.
- Dead Letter Topic Suffix - The suffix that will be appended to the main topic in order to generate the dead letter topic. This can be an expression that resolves to a String. If not set then messages will not be sent to a dead letter topic. e.g. If the configured topic is
customersand the suffix is-dltthen the name of the topic to which dead letter messages will be sent iscustomers-dlt - Retry Topic Suffix - The suffix that will be appended to the main topic in order to generate the retry topics. This can be an expression that resolves to a String. Depending on the topic suffixing strategy the retries will also be suffixed with the delay value or a simple index. If not set then messages will not be sent to a retry letter topic, blocking retries will be used and messages will be sent to the dead letter topic (if configured). e.g. If the configured topic is
customers, the suffix isretryand the number of attempts is 3 then the messages will be sent to:customers-retry-0andcustomers-retry-1 - Delay type (BackOff type)
- Default - Use the default fixed back off policy with a delay of 1 second
- Fixed - A back off policy that pauses for a fixed period of time before continuing. The delay in milliseconds can be configured when this is picked
- Exponential - A backoff policy that increases the back off period for each retry attempt up to a limit. The initial interval controls the initial delay for the first retry, and the multiplier controls by how much the delay is increased for each subsequent attempt. The delay interval is capped at the max interval. The initial / max interval in milliseconds and the multiplier can be configured when this is picked. e.g. when the initial interval is 100, the max interval is 1000, the multiplier is 2 and the number of attempts is 4 the number of delays will be: 100, 200, 400
- Exponential Random - A backoff policy that increases the back off period for each retry attempt up to a limit and uses randomized delays. The initial interval controls the initial delay for the first retry, and the multiplier controls by how much the delay is increased for each subsequent attempt. The delay interval is capped at the max interval. The initial / max interval in milliseconds and the multiplier can be configured when this is picked. e.g. when the initial interval is 100, the max interval is 1000, the multiplier is 2 and the number of attempts is 4 the number of delays might be: 152, 320, 675 (random distributed within the ranges of [100-200, 200-400, 400-800])
- Uniform - A back off policy that pauses for a random period of time before continuing. The min / max back off period in milliseconds can be configured when this is picked.
- Fix delay topic strategy - Whether to use a single or multiple topics when using a fixed delay. By default, it will use a single topic.
- Topic suffixing strategy - Whether the retry topics will be suffixed with the delay for that topic or a simple index. This is in addition to the configured retry topic suffix. By default, they will be suffixed with the index value.
- Auto create topics - Whether the retry and dead letter topics should be automatically created.
- Default - Topics will be auto created based on a global configuration of the Flowable runtime
- Yes - Always auto create topics
- No - Never auto create topics
- Expression - An expression that evaluates to
trueorfalsethat will be evaluated to decide whether the topics should be auto created. - Number of partitions - The number of partitions for the automatically created topics. Used only when auto create topics is evaluated to
true. This can be an expression that evaluates to an integer or a String that can be parsed as such. By default, it is 1. - Replication factor - The replication factor for the automatically created topics. Used only when auto create topics is evaluated to
true. This can be an expression that evaluates to an integer or a String that can be parsed as such. By default, it is 1.
Pipeline
The pipeline configuration is the same for all channels. See Inbound Pipeline for more details.
RabbitMQ
Technical configuration
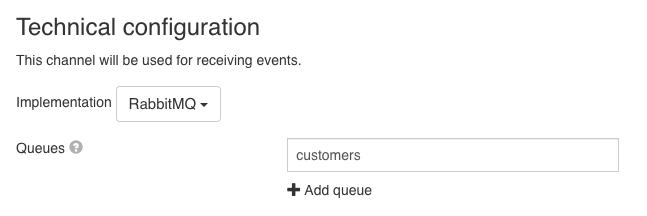
In this section the RabbitMQ queues that the channel should listen to need to be configured. It is possible to provide multiple queues that would be consumed. An expression can be used to determine the name of the queue that should be consumed.
Advanced configuration
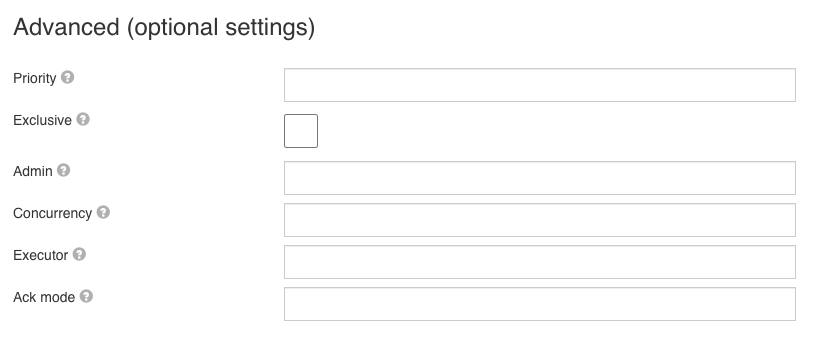
All options here are optional and allow using expressions. The available options are:
- Priority - See RabbitMQ Priority Queue Support for more information
- Exclusive - Whether the consumer for this channel should exclusively consume events from the queue
- Admin - Name of a Spring bean that resolves to a
org.springframework.amqp.rabbit.core.RabbitAdmininstance, which needs to be used to connect to the queue. If not configured, it will use the defaultRabbitAdminbean. - Concurrency - A numerical value or an expression resolving to a number, that is used to configure how many RabbitMQ listeners should be started.
- Executor - Name of a Spring bean that resolves to a
org.springframework.core.task.TaskExecutorinstance which will be used for receiving events. Leave blank to use the default. - Ack mode - Possible values: NONE, MANUAL, AUTO. See the RabbitMQ documentation for more details.
Pipeline
The pipeline configuration is the same for all channels. See Inbound Pipeline for more details.
JMS
Technical configuration

In this section the JMS destinations that the channel should listen to needs to be configured. An expression can be used to determine the name of the destination that should be consumed.
Advanced configuration

All options here are optional and allow using expressions. The available options are:
- Message selector - An expression that is used to configure which JMS messages should be received. Please check your JMS vendor documentation to know which syntax to used.
- Subscription - Configures the name of the subscription when listening to JMS messages. Please check your JMS vendor documentation to know which syntax to used.
- Concurrency - A numerical value or an expression resolving to a number, that is used to configure how many JMS listeners should be started.
Pipeline
The pipeline configuration is the same for all channels. See Inbound Pipeline for more details.
AWS SQS
Technical configuration

In this section the AWS SQS queue that the channel should listen to needs to be configured. An expression can be used to determine the name of the queue that should be consumed.
Advanced configuration
All options here are optional and allow using expressions. The available options are:
- Maximum number of messages - A numerical value (>=0 and <= 10) or an expression that resolves to a number, that indicates the maximum number of messages to return when requesting messages.
- Visibility timeout - An ISO 8601 Duration value that indicates the duration that the received message is hidden from subsequent retrieve requests after initial retrieval
- Wait time - An ISO 8601 Duration value that indicates the duration for which a call to retrieve a message waits for messages to arrive in the queue before returning. See the AWS SDK documentation about long polling for more information.
- Message deletion policy - Value indicating the deletion policy of received messages. If left blank, a default value will be used (No redrive). Allowed values:
- On Success - Deletes message when successfully executed. If an exception is thrown during message processing, the message will not be deleted.
- No Redrive - Always deletes message in case of success (no exception thrown). On failure (exception thrown) deletes messages only if the queue has no redrive policy.
- Always - Always deletes message in case of success (no exception thrown) or failure (exception thrown) during message processing.
Pipeline
The pipeline configuration is the same for all channels. See Inbound Pipeline for more details.
Email
Technical configuration

In this section the email IMAP URL that the channel should listen to needs to be configured. An expression can be used to determine the URL that should be consumed.
Advanced configuration

All options here are optional and allow using expressions. The available options are:
- Subject correlation pattern - A regex pattern that will be used to extract the subject correlation parameter. All the groups from the regex will be concatenated to create the subject correlation. As an example, to extract the case id within brackets from the subject as a correlation parameter, use this regex:
\[(CAS-.*)\]so, "[CAS-12345] Email subject" would result inCAS-12345being the subject correlation parameter. - Should delete messages - Whether messages should be deleted after they've been received.
- Should mark messages as read - Whether messages should be marked as read once they've been received.
- Polling rate - An ISO 8601 Duration value that will be used for setting the frequency at which the messages will be polled from the mail server.
- Max messages per poll - Number indicating how many messages should be processed per polling interval. Setting this to -1 will process all available messages in a single polling interval.
- Supports IDLE - Whether the mail server supports IMAP IDLE. When this is true then the polling rate is not used, since we are going to receive the messages via push from the mail server.
- User Flag - The name of the flag to use to flag messages when the server does not support the \Recent, but supports user flags. If not set the global default will be used.
- Username - The username that should be used to authenticate the connection with the Mail Server
- Password - The password that should be used to authenticate the connection with the Mail Server. This doesn't have to be hardcoded password, it can be a SpEL expression that will load the password from system properties.
- Authentication Bean name - The name of the bean which is an instance of
javax.mail.Authenticatorthat will be used as the authenticator. If this is set the username and password are not used. - Custom properties - A mail consumer can have many custom mail properties set. These can be set here.
Tenant Detection

The email channel provides a tenant detection section that allows you to configure to which tenant the received email event should be sent.
There are the following options:
- No tenant ID detection - The event will be sent to the same tenant in which the channel is deployed
- Fixed tenant ID - Allows you to provide a fix value for the tenant in which the events should be sent to. When set, every event received via this channel will be sent to the provided tenant.
- Extract using a matching regex group from the E-Mail Subject - Allows you to configure a regex pattern that will be used to extract the tenant ID. All the groups from the regex will be concatenated to create the tenant ID. As an example, to extract the tenant ID within brackets from the subject, use this regex:
\[TENANT-(.*)\]so, "[TENANT-flowable] Email subject" would result inflowablebeing the tenant ID. - Custom delegate bean implementation - Allows you to provide an expression that resolves to a
org.flowable.eventregistry.api.InboundEventTenantDetectorimplementation on the Flowable servers on which this channel model will be deployed.
REST
Technical configuration
v3.14.0+In this section the REST inbound channel can be configured. The only options this channel type provides are security related. A modeler has to provide either a list of userIds or groupIds that have access to the channel. The channel will then be made available automatically at the following endpoint:
/platform-api/channel-definitions/key/{channelDefinitionKey}/events
HTTP headers are also passed to the event if the event contains a header field with the same name as the HTTP header.
Pipeline
The pipeline configuration is the same for all channels. See Inbound Pipeline for more details.
Custom
Technical configuration

In this section the name of a Spring bean that resolves to a org.flowable.eventregistry.api.InboundEventChannelAdapter instance that will receive events needs to be provided.
Pipeline
The pipeline configuration is the same for all channels. See Inbound Pipeline for more details.
Pipeline
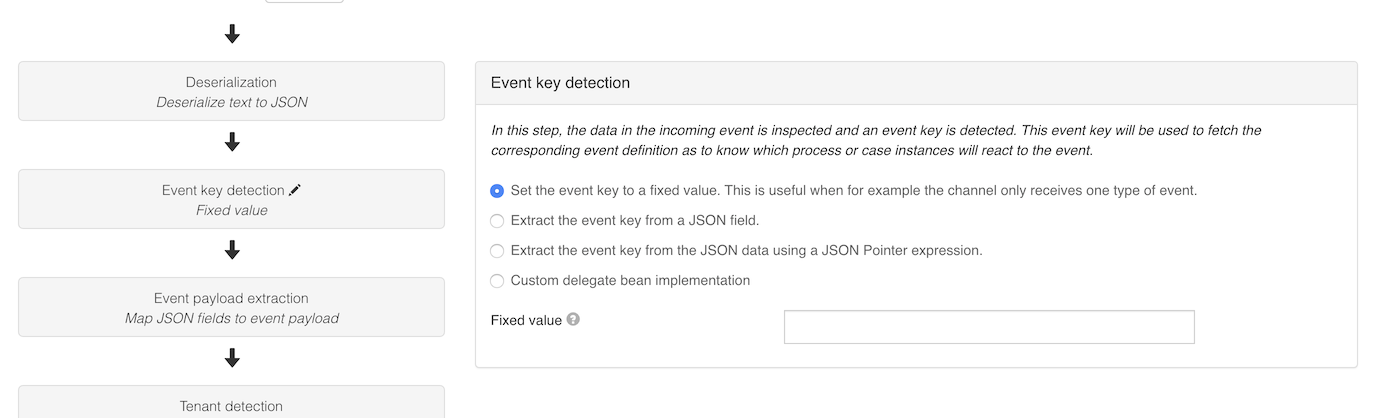
The third section configures the pipeline of the channel, as explained above. Every event that is received, passes through this pipeline, which is also indicated in the UI:

The serialization format of the event (XML, JSON or Custom) can be selected in the dropdown above the pipeline steps. Switching this format changes the possible options in certain steps of the pipeline. For example, when selecting JSON, the Event key detection step can be configured to use a JSON Pointer expression while for XML an XPath option becomes available.
The small option Use default pipeline steps at the top is checked by default. This means that by default, the pipeline consists of five steps that are typically used by Flowable users. It's possible to have a fully custom pipeline implementation, but unchecking the checkbox and providing the proper Spring bean in the Flowable configuration (see the info icon for more details).
In the UI above, each gray rectangle is clickable and shows the details of that step when clicked. A pencil icon next to the step shows which step is currently being edited.