Introduction
In Flowable Work, critical business data is continuously indexed as users are working with processes, cases, tasks, etc. Indexing in this context means that the data is transformed, enriched, and then ingested by Elasticsearch. By having the data indexed in Elasticsearch, this enables fast searches (regular, full-text or even fuzzy) and analytical queries. Flowable Work exposes API’s (in REST and Java) to query and work with the data efficiently.
This document describes in detail the way data is indexed and possible extensions/enhancements that are available out-of-the-box within Flowable Work.
Furthermore, this document explains:
-
How variables are indexed automatically and how the values of those variables get indexed for easy searching.
-
How the default index mappings can be extended to store additional data or change the default way that data is stored.
-
How to create custom search aliases or dynamic queries can be defined to build powerful dashboards.
-
Why reindexing is sometimes needed and how it is triggered.
The general principles also apply to Flowable Engage (for conversations and messages), but the specifics are described in another document.
Elasticsearch Functionality
Flowable Work is designed in such a way that there only exists a thin layer around Elasticsearch functionality. As described in the following sections, as much as possible (mapping, querying, etc.) are exposed in the 'native' Elasticsearch format. The design decision behind this is that whenever a new feature gets added to Elasticsearch, this means it is automatically available for use with Flowable indexing.
Mapping Definitions
Elasticsearch indices need a mapping definition that defines how the data in the index is structured, what type of analysis needs to happen on which fields, etc. More information about mappings can be found in the Elasticsearch documentation.
On the bootup of the Flowable server, the Elasticsearch instance (which can be a cluster of
multiple nodes) is checked to have the correct mapping definitions.
The default mappings in Flowable are defined in mapping configuration files that
ship with the product. Their default location on the classpath is
com/flowable/indexing/mapping/default. These mapping configurations are
versioned, and Flowable automatically upgrades the mappings on startup (if possible).
 note
noteIt is possible to override the default mapping configuration files completely
or add custom mapping configuration by placing mapping files in either
com/flowable/indexing/mapping/default or com/flowable/indexing/mapping/custom
and setting flowable.indexing.enable-default-mappings to false in the
application.properties file.
An example mapping file looks as follows:
{
"name": "tasks",
"version": 1,
"filter": {
"types": [ "TSK" ]
},
"mappings": {
"dynamic": "strict",
"properties": {
"assignee": {
"type": "keyword"
},
"category": {
"type": "text"
},
"claimTime": {
"type": "date"
},
"createTime": {
"type": "date"
},
"description": {
"type": "text",
"copy_to": [
"full_text_typeAhead"
]
}
}
}
}
Flowable creates a unique name for each of the default indices. The name starts with the value of the flowable.indexing.index-name-prefix property if set. If not set, the name starts with flowable.project-name or the empty string if that one is missing. Next comes the actual index name (e.g., my-project-tasks), followed by a timestamp suffix.
For each such index, an alias is created with the 'regular' name. For example,
the alias my-project-tasks might point to the index my-project-tasks-<timestamp>.
This is important for reindexing, as during a reindex the alias points to the
original index until indexing is completed and then the alias is mapped to the
new index.
Indexed Data
Flowable creates the following indices by default:
-
work: Contains the 'work instances'. A work instance is a root process or case instance.
-
case-instances: Contains all case instances (runtime and historical).
-
process-instances: Contains all process instances (runtime and historical).
-
tasks: All tasks (process, case, or standalone) get indexed here.
-
users: Users and user information gets indexed here. When using a third party user provider such as LDAP, there won't be data indexed.
-
content items: Data around content items (such as uploaded documents in the context of process and case instances).
-
plan-items: Stores information about plan item instances of a case instance and this is useful for heat maps or analyzing case instance optimizations.
-
activities: Stores information about activities executed as part of process instance executions and this is useful for heat maps or analyzing process instance optimizations.
As of version 3.14.0 and onwards the plan-items, activities and content items are not indexed by default. To configure the indices which are enabled, use the following property configuration:
flowable.indexing.enabled-indices=case-instances, process-instances, work, tasks, activities, plan-items, content-items
The data which is stored for the particular index is defined by the default index mapping files and differs from type to type.
The work, case-instances, process-instances and tasks indices share some common data though, and they contain:
-
variables and identityLinks.
-
fields for indicating the instance information (e.g., the case instance id and name for a task in a case).
-
fields to indicate the parent scope: parentScopeId, parentScopeType and parentScopeName (if the instance has a parent). For example, a child process instance of a case instance would have the id and name of the parent case and 'cmmn' as type.
-
fields to indicate the parent scope definition: parentScopeDefinitionId, parentScopeKey, parentScopeDefinitionName. For example, a child process instance of a case instance would have the definition id, key, and of the deployed root case model.
-
fields to indicate the root scope: rootScopeId, rootScopeType and rootScopeName. For example, a nested process (does not matter how deeply nested) of a root case instance would have the id and name of the root case instance. The type would be 'cmmn'.
-
fields to indicate the root scope definition: rootScopeDefinitionId, rootScopeKey, rootScopeDefinitionName. For example, a nested process (does not matter how deeply nested) of a root case instance would have the id, key, and name of the deployed root case model.
Indexing Variables
Variables are typically very important when it comes to indexing, as typically processes and cases gather a lot of data through forms, automated tasks, or other ways. This data is often utilized to build dashboards, analytical pages or reports that are used to gain new insights or to improve the way users can work with process or cases. Of course, fast querying of instances based on variable data is possible too.
This particular functionality has often been a problem performance-wise for relational databases when the amount of data gets to a certain size. For this reason, Flowable comes with indexing of variables out-of-the-box in a query-friendly but extensible way.
Variables are automatically indexed for the following indices:
-
Work instances (/work)
-
Case instances (/case-instances)
-
Process instances (/process-instances)
-
Tasks (/tasks)
Variables are stored as a nested collection on each of JSON documents representing a work, process, case instance, or task. When querying for a task directly in Elasticsearch for example, the response contains a variable array (omitting irrelevant parts):
{
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_source": {
"variables" : [ ]
}
}
]
}
}
As of version 3.14.0, large variables won't get indexed by default to Elasticsearch to prevent storing too much data in Elasticsearch, which typically is not used for data retrieval or querying. A large variable in this context means a big JSON or other big variable types. Technically it means any variable that has a byte array reference and value. This default behaviour can be fully disabled with the following property
flowable.indexing.filter.ignore-large-variables=false
It's also possible to define a list of variables which always should be indexed with the following property
flowable.indexing.filter.always-include-variables=myVariable,myOtherVariable
By enabling the following property an incident is created when a variable is ignored during indexing
flowable.indexing.variable-incident-reporting.enabled=true
Variable Values
Each variable is stored as a nested JSON document. Every variable document has, at a minimum the following fields:
-
name: The name of the variable, for example, the name of the form field, the variable set in a service task, a mapped in/out parameter, etc.
-
type: The type of the variable (text, number, date, etc.). This corresponds directly to the types that are available in the Flowable engines.
-
id: the internal (database) id of the row in the variable table. This is used internally (e.g., for tracking updates).
The actual value of a variable is the most important aspect. The value is stored in a dedicated typed field, which depends on the type of the variable:
-
dateValue: for date (regular Java dates or Joda-Time dates) variables, stored as an Elasticsearch date field.
-
booleanValue: for boolean variables, stored as an Elasticsearch boolean field.
-
numberValue: for number (integer/long/short/…) variables, stored as an Elasticsearch long field.
-
decimalValue: for decimal (double/float) variables, stored as an Elasticsearch double field.
-
textValue: for textual and UUID variables, stored as an Elasticsearch text (full-text searchable) field. Furthermore, the same textual value is stored in the textValueKeyword field, which allows for exact queries (non-full-text search matching).
-
jsonValue: for JSON variables, which are stored as-is for retrieval. If there is a need for querying or sorting on a field of a JSON variable value, that value needs to be extracted.
There is also a rawValue field, which gets a copy of the variable value with the type serialized to text. For example, for a number field, it would contain the number as a string, for a boolean it would contain 'true' or 'false', etc. This field does not get indexed and cannot be used in queries for e.g. match queries.
Best practice: avoid storing Java serializable variables (like storing a java.util.List, java.util.Map, or other variables). They make querying impossible and can lead to subtle bugs in application code (e.g., serialization/deserialization between JVM versions causes issues). For lists or maps, use a Jackson JsonNode instead. The ObjectMapper has methods to convert between JSON and objects easily.
noteThere also is a field 'variableTypeAhead' defined in the mapping files. This field is used internally when a variable is marked as needing a full-text search as part of its owning entity (case/process/task). There is more about this field in a later section.
Variable Scoping
Often, a case or process model can have 'child' cases or processes which again can have their own 'child' cases or processes. Technically this forms a 'tree' structure: the root case or process is the root of the tree, and the lower level processes or cases are the leaves.
The notion of a tree is essential, as it defines scoping rules for variables:
-
Each element of the tree stores variables by default on its own element. A form on a child process/case instance stores those form variables on that process/case instance by default.
-
Explicit in/out mappings can be used to copy variables up and downwards the tree.
-
In the Flowable products (not in the open source engines) it is possible to reference the parent or the root in forms, expressions, etc. irrespective of how deeply nested in the tree.
Given this context, every variable includes scope information that can be used to pinpoint the origin of the variable precisely:
-
scopeId: The instance (e.g., process or case instance) id where this variable was created.
-
scopeType: The type (e.g., BPMN or CMMN) of the scope on which this variable was created.
-
scopeHierarchyType: The 'relationship' in the tree from where this variable value was added and where it originally came from. It can be PARENT, ROOT, or TASK (for task-local variables).
-
scopeDefinitionId: The definition (e.g., process or case definition) id corresponding to the scope where this variable originated from.
-
scopeDefinitionKey: The definition (e.g., process or case definition) key corresponding to the scope where this variable originated from.
With this information, queries like 'give me all variable values with name ABC for root case with definition XYZ' are easily expressed and execute quickly as all the information is natively indexed.
How variables are propagated in the tree needs additional explanation. When a new instance (work/process/case/task) is created, the tree is traversed upwards to gather the parent and root variables. When a new variable gets set (e.g., in a service task), the tree is traversed downwards to propagate the variable to the child instances (work/process/case/task).
Let us use an example to clarify the propagation. First, assume that we have the following tree structure (and assume for simplicity all instances are created on the start of the root case):
root case
- case CA
- process PA
- process PB
- task TA
- task TB
- case CB
- process PC
- task TC
Assume that the root case has a start form. Any form variables are set on the root case and are available to all children in the tree. This means that each instance in this tree (CA/CB/PA/PA/PB/PC/TA/TB/TC) has this variable in its indexed JSON document with:
-
scopeDefinitionId/Key the key of the root case.
-
scopeId is the case instance id of the root case.
-
scopeType is CMMN.
Technically, the lookup progresses upwards: on the creation of the child case/process/task the tree is inspected and the root variable is found and indexed.
Now suppose the root case contains a service task that gets executed sometime after starting the case instance. When that service task sets a variable (or for that matter, anything that sets a variable), the same propagation mechanism sets the variable on all its children in a downwards manner.
In the index, the data looks as follows:
{
"id": "VAR-d06e1552-8151-11e9-8e41-38c986587585",
"name": "startFormField",
"type": "string",
"textValue": "startValue",
"textValueKeyword": "startValue",
"rawValue": "startValue",
"scopeId": "CAS-cdb780ce-8151-11e9-8e41-38c986587585",
"scopeType": "cmmn",
"scopeDefinitionId": "CAS-0f8996a7-8151-11e9-ae26-38c986587585",
"scopeDefinitionKey": "myRootCase",
"scopeHierarchyType": "root"
}
Variables that are set on a lower level task, for example, on task TB only exist on that task:
{
"id": "VAR-d06e1552-8151-11e9-8e41-23c986587585",
"name": "taskFormField",
"type": "string",
"textValue": "test",
"textValueKeyword": "test",
"rawValue": "test",
"scopeId": "TSK-cdb780ce-8151-11e9-8e41-38c598727585",
"scopeType": "bpmn",
"scopeDefinitionId": "PRC-0f8996a7-8151-11e9-ae26-38c986587585",
"scopeDefinitionKey": "processPB"
}
Parent variables are indexed using the same mechanism, but instead of being applied to the whole tree they are only applicable to one level. For example, for task TC, a variable from its parent case could like like:
{
"id": "VAR-cf4dd840-8151-11e9-8e41-38c986587585",
"name": "initiator",
"type": "string",
"textValue": "admin",
"textValueKeyword": "admin",
"rawValue": "admin",
"scopeId": "CAS-cdb780ce-8151-11e9-8e41-38c986587585",
"scopeType": "cmmn",
"scopeDefinitionId": "CAS-0f8996a7-8151-11e9-ae26-38c986587585",
"scopeDefinitionKey": "myCase",
"scopeHierarchyType": "parent"
}
If the parent and the root are the same (e.g., in the example above for case CA and CB), the variables get indexed twice, but with different scope information. This is to be consistent with how the form engine and the REST endpoints handle form variables.
Variable Updates
In the previous section, explained how each work/process/case/task instance gets variables indexed from itself, its parent, and the root. The obvious next question is how updates are handled.
Updates to variables are propagated through the whole tree for all instances (work/process/case/task) that have visibility on these variables. This means that an update on a root variable is propagated to all nodes. An update in the middle of a tree is propagated to the direct child (as the variable is a parent variable for that child).
Thus no special processing is required for data changes: the Flowable indexing logic ensures that updates are propagated correctly, and the index matches the real variable data.
Variable Index Filtering
v3.13.0+By default, Flowable indexes all variables. However, it is a good idea in general to think about what data should be indexed and limit the data to a reasonable amount. Storing all variables to the index can be a performance issue or not a good idea in general for compliance reasons. For example to avoid replicating sensitive personally identifiable information (PII) in the index.
That's why Flowable Design enabled the possibility to specify whether to include certain variables for indexing or to exclude specific variables from being written into the index.
In BPMN and CMMN it's possible to configure on the root level of the model which variables should be stored using the Indexing filter type and Indexing filter variable name properties:
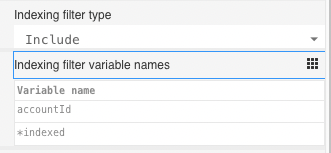
If you run into a 413 Request Entity Too Large error, the first thing to check is if you have a lot of variables in your process or case
and if it would be possible to exclude some of them from being indexed.
Variables can be filtered either by including or excluding which is specified by setting the Indexing filter type to:
Includeonly certain variables for indexing (allowlist approach)Excludespecific variables from being written into the index (blocklist approach)
We recommend using the Include option, as it is more explicit, which is also de default in Flowable Design.
NOTE:
noteIt is important to understand that variables filtered from indexing are still available in the Flowable Engine, but they are not stored in the index.
Variable name matching
Variables can be filtered by exact name, prefix wildcard, suffix wildcard or both e.g. var, var*, *var, *var*.
This way it would also be possible to filter variables by name pattern, e.g. *_indexed would only allow variables named myvar_indexed, myothervar_indexed, etc.
Variables without a scope prefix are matched for all scopes by default. The main use-case for this feature is to mute data entirely from the index, which is ensured by this default behavior.
Scoped matching
It is possible to exclude only ROOT or PARENT variables from being indexed by using the root. or parent. prefix in the indexing filter variable name.
Using root.bank* would match the variable bankAccount for the root scope only, but not match for the parent and self scope.
Therefore, if the parent scope contains a 'bankAccount' variable, it would still end up in the index for those scopes.
Hierarchies
It is strongly recommended to define variable index filters on the root process or case only to keep things understandable and maintainable.
Index filters are inherited by child processes and cases. If you define the index filters on a child process or case it replaces the index filters of the parent process or case. The indexing filter is applied to the whole hierarchy of a process or case instance. This means that if a variable is excluded from indexing on the root level, it will also be excluded from indexing on all child tasks and sub-processes.
noteIn case multiple index filters are available in the hiearchy, only the most specific (closest) one is applied. Filter definition lists are NOT merged.
Mapping Extensions
In some cases, the data indexing in the default mapping files is insufficient. This could be because a calculated field needs to be added; data needs to be fetched from some other data store, etc.
A Mapping Extension needs to be defined to extend the default index mappings.
These mapping extensions are JSON files that are put on the classpath in
the location com/flowable/indexing/mapping-extension/custom/. These mapping
extension files are read on server bootup. Thus when changes are needed, a server
reboot is required. Multiple extensions for the same index are possible.
Let us look at the structure of such an extension. Assume this file named, my-task-mapping-extension.json, is placed in the correct classpath location:
{
"key": "my-task-mapping-extension",
"extends": "tasks",
"version": 1,
"properties": {
"customField1": {
"type": "keyword"
},
"customField2": {
"type": "geo-point"
}
}
}
At the top of the configuration, there are the following fields:
-
key: A mandatory field that uniquely identifies this extension. This key is important as it is used (in combination with the version) to determine if an upgrade is needed to the Elasticsearch mapping file.
-
extends: A mandatory field that defines which index mapping this configuration extends and can be any of the default indices (
work,case-instances,process-instances,tasks,users,plan-items, oractivities). -
version: An optional field (if missing then version 0 is assumed). Sequentially increment this field when changes are made to the extension. On server bootup, the mapping is automatically upgraded, if Elasticsearch allows the mapping change upgrade.
The properties field is where the actual extension is defined. The content of this property is taken as-is and merged with an existing mapping file before it is sent to Elasticsearch. As such, the format to use is the native Elasticsearch mapping definition format.
The properties are added after the original mapping is processed. This means that existing default property mappings are overridden as they replace the existing default definition.
Providing Data For Mapping Extensions
The previous section described the mechanism for extending the index mapping and explained the structure of the data. The section shows how to provide data for that structure and define how it needs to be returned in the APIs.
Providing the data is done by implementing the
com.flowable.indexing.api.PlatformIndexedDataEnhancer interface (or extending the
com.flowable.indexing.impl.IndexedDataEnhancerAdapter) and putting that bean in a
Spring @Configuration class (or other Spring-compatible definitions).
Multiple beans can be defined by implementing the same interface.
The PlatformIndexedDataEnhancer interface has callback methods that are called when data gets indexed. The entity in question gets passed along with the JSON data (as an ObjectNode instance). Note that at the data creation point, no knowledge exists about which index this data is added (because Flowable supports mapping the same data to multiple indices).
The methods on the interface follow the same pattern for each instance type:
- one method for indexing specific data of the historic instance.
For example, for case instances, the following methods exist:
enhanceHistoricCaseInstanceReindexData
Similarly, named methods exist for process instances, case instances, tasks, activities and plan item instances (covering all the default indices).
Let us look at an example where the task JSON is enhanced:
import com.flowable.indexing.api.IndexingJsonConstants;
public class CustomIndexedDataEnhancer extends IndexedDataEnhancerAdapter {
@Override
public void enhanceTaskReindexData(HistoricTaskInstance taskInstance, ObjectNode data,
IndexingManagerHelper indexingManagerHelper) {
if (data.has(IndexingJsonConstants.FIELD_VARIABLES)) {
JsonNode variables = data.get(IndexingJsonConstants.FIELD_VARIABLES);
if (!variables.isNull() && variables.size() > 0) {
for (JsonNode variableNode : variables) {
if ("customerName".equals(variableNode.get(IndexingJsonConstants.FIELD_VARIABLE_NAME).asText())) {
data.put("customProperty1", variableNode.get(IndexingJsonConstants.FIELD_VARIABLE_TEXT_VALUE).asText());
}
}
}
}
}
}
Here, the variable array is retrieved. If one of the variables is the
customerName variables, the variable is copied to the customProperty1 on the
root level of the JSON for the task. This may facilitate doing keyword queries against
the value later.
The associated mapping extension would be:
{
"key": "my-task-mapping-extension",
"extends": "tasks",
"version": 1,
"properties": {
"customProperty1": {
"type": "keyword"
}
}
}
The last piece of the puzzle is to define how this data is to be returned.
There is a dedicated result enhancer for each type (e.g.,
com.flowable.platform.service.task.TaskResultMapper.Enhancer).
Continuing the example from above, assume we want to put the
customProperty next to the regular variables:
public class MyTaskEnhancer implements TaskResultMapper.Enhancer {
@Override
public void enhance(TaskSearchRepresentation response, JsonNode indexedData) {
if (indexedData.get("customProperty1").hasNonNull()) {
response.getVariables().put("customProperty1", jsonNode.get("customProperty1").asText());
}
}
}
Custom Result Mappers
In case the above is insufficient, it is also possible to replace the entire ResultMapper
class that is responsible for mapping the data from the index to the REST response. There is a dedicated result mapper for each type (e.g., TaskResultMapper, CaseInstanceResultMapper, etc.).
When replacing the entire class, your implementation is responsible for creating the entire response (although it is possible to extend from the default implementation):
public class CustomTaskJsonMapper extends TaskJsonMapper {
@Override
public TaskSearchRepresentation convert(JsonNode jsonNode) {
TaskSearchRepresentation taskResponse = super.convert(jsonNode);
if (jsonNode.get("customProperty1").hasNonNull()) {
taskResponse.getVariables().put("customProperty1",
jsonNode.get("customProperty1").asText());
}
return taskResponse;
}
}
When putting this class with @Bean in your custom configuration, it will replace the default one.
Note how this example extends the default implementation of TaskJsonMapper to
avoid having to duplicate the default fields.
Extracting Variable Values Into Custom Variable Fields
v3.2.1+For some use cases, the default way variable values are indexed is insufficient. For example, for certain fields, a different tokenizer or analyzer is required to support different languages or different ways of indexing the data.
For regular indexed fields, changing this is possible by adding a
mapping extension
that overrides the default mapping for that field or adds a copy_to
to another field with a different configuration.
For variables, as they are nested within the variables property and have an
extensive way of tracking updates and deletions, this is not simple.
For this purpose, one uses a variable extractor in the mapping extension. For example:
{
"version": 1,
"extends" : "tasks",
"key": "example-variable-properties-extractor",
"variableProperties": {
"customAnalyzedField": {
"type": "text",
"analyzer": "whitespace"
},
"customAnalyzedFieldKeyWord": {
"type": "keyword"
}
},
"variableExtractors": [
{
"filter": {
"name": "customVariable",
"scopeDefinitionKey": "oneTaskProcess"
},
"to": "customAnalyzedField",
"type": "string"
},
{
"filter": {
"name": "customVariable",
"scopeDefinitionKey": "oneTaskProcess"
},
"to": "customAnalyzedFieldKeyWord",
"type": "string"
}
]
}
What is unique about a mapping extension
is there is now a variableProperties property. Similar to the properties of
a mapping extensions, the content of this property
is taken as-is and added under the variables properties in the index mapping.
In this example, two fields are added:
-
a
customAnalyzedFieldwith a custom analyzer -
a
customAnalyzedFieldKeyWordwith the keyword type
This part defines the structure of the new properties in the index. The second part is how the values get mapped into these new fields, which is done by the variableExtractors section.
This is an array of one or more extractors that require at a minimum:
-
A filter: A variable extractor has a filter that defines when the extractor is applied. Any of the fields of the mapping can be used here. The filter is checked on variable create, update, or delete. An explicit
nullvalue means that no value should be set for the field (e.g.,"scopeDefinitionName": nullmeans that only those instances that have no name for the definition match this filter). -
A to: The to defines the name of the field to map into.
-
A type: The type in the extractor is required as it configures how the JSON field is mapped into the actual field. The supported types are:
-
boolean
-
date
-
double
-
integer
-
long
-
short
-
string
-
uuid
-
null
-
noteThese types are the same variable types supported in the Flowable engines.
In the example above, there are two extractors (lines 18-23 and 26-31)
that both work on the
same customVariable in the oneTaskProcess, as defined by the filter.
One first extractor maps it to the customAnalyzedField field (line 22),
the other to the customAnalyzedFieldKeyWord field (line 30).
These fields are defined in lines 7 and 11 above in variableProperties.
When looking at the index, these new fields are part of the variables property
of tasks, case, process, or work instances:
"variables": [
{
"name": "customVariable",
"type": "string",
"textValue": "test",
"textValueKeyword": "test"
"customAnalyzedField": "test",
"customAnalyzedFieldKeyWord": "test",
},
...
]
The textValue and textValueKeyWord are the default fields when
using a String variable.
The customAnalyzedField and customAnalyzedFieldKeyWord were added
by the configuration above.
These fields can now be used in queries (see the
section on custom queries):
{
"version": 1,
"name": "example-custom-query",
"type": "query",
"sourceIndex": "tasks",
"customFilter": {
"bool": {
"must": [
{
"nested": {
"path": "variables",
"query": {
"bool": {
"must": [
{
"term": {
"variables.name": "customVariable"
}
},
{
"match": {
"variables.customAnalyzedFieldKeyWord": "test"
}
}
]
}
}
}
}
]
}
}
}
Extracting Values from JSON Variables
v3.2.1+The Flowable engines support storing variables as JSON (as ObjectNode or ArrayNode).
When these variables are indexed, the value gets stored as-is in the jsonValue field.
noteElasticsearch does not support different types for the same property.
Hence the reason the jsonValue gets stored without any additional analyzing
or indexing out of the box.
When properties of a JSON variable need to be used in queries or sorting,
they need to be extracted using a variableExtractor.
Such an extractor is part of a mapping extension configuration and looks as follows:
"variableExtractors": [
{
"filter": {
"name": "customer",
"scopeDefinitionKey": "myDefinition"
},
"path": "/nestedField/customerName",
"to": "extractedCustomerName",
"type": "string"
}
]
A variable extractor has a filter that defines when the extractor is applied.
Any of the fields of the mapping can be used here. The filter is checked on
variable create, update or delete.
An explicit null value means that no value should be set for the field
(e.g., "scopeDefinitionName": null would mean that only those instances
that have no name for the definition match this filter).
In this example, when a variable with the name customer is created, updated,
or deleted, and the definition of the case or process definition is myDefinition,
the extractor is applied.
The path is a JSON Pointer expression that defines the path to the property that needs to be extracted. The to parameter is the name of the variable which contains the extracted value.
Here, the customerName of the customer JSON variable can be found under
the nestedField in the customerName property,
and it is mapped to extractedCustomerName.
This means that in the index, there is another variable (arguably
this is a virtual variable as there is no counterpart in the process or
case instance) indexed with the name extractedCustomerName.
However, contrary to the JSON value, this is a first-class variable, and it
can now be used in querying or sorting.
The type in the extractor is essential, as it configures how the JSON field is mapped to the actual field. Supported types are:
-
boolean
-
date
-
double
-
integer
-
long
-
short
-
string
-
uuid
-
null
noteThese types are the same variable types supported in the Flowable engines.
This type is interpreted as a variable type, meaning that the rules described in variable values apply.
In this example, as the type is string, this means that the extractedCustomerName
has a textValue and textValueKeyword like any other string variable.
Using this variable extractor, there are now two entries in the index:
one for the original (JSON) variable and one for the extracted value.
Both are stored as a variable under the variables property and thus can be used
in queries, sorting, etc.
"variables": [
{
"name": "customer",
"type": "json"
"jsonValue": {
"nestedField": {
"customerName": "John Doe",
"customerAge": 42
}
},
...
},
{
"name": "extractedCustomerName",
"type": "string",
"textValue": "John Doe",
"textValue": "John Doe",
"textValueKeyword": "John Doe"
},
...
]
Using Variable Values For Full-Text Search
In some situations, using variables values in a full-text query for finding cases, process, work, or task instances is required. To avoid potentially many mismatches by including all variables in the index in a search, it is possible to precisely define which variables are taken into account during the full-text search.
To define the variables, a mapping extension with a fullTextVariables section is used:
{
"key": "my-task-mapping-extension",
"extends": "tasks",
"version": 1,
"fullTextVariables": [
{
"name": "customerName",
"scopeDefinitionKey": "myRootCase"
}
],
"properties": {
...
}
}
The fullTextVariables property is an array of variable matching definitions. Any field (see above) that is indexed for a variable can be used in this definition. In the example here, customerName, when defined in a case or process with definition key myRootCase matches this definition. Note that when omitting the scopeDefinitionKey the specification would match the customerName variable in any deployed case or process.
The value of all variables that match the definition(s) are copied into a field fullTextVariables that is defined on the JSON document of the instance (work/process/case/task) itself and can, therefore, be used to query in a full-text manner. In case multiple variable definitions are configured, all the variables are copied into the full-text field (e.g., we want to query based on customer name, location, or description at the same time).
Again looking at the example above, this means that the value of customerName is indexed both in the variables array of a task JSON document and copied to the fullTextVariables for full-text search. A query, give me all tasks where fullTextVariables contains with 'abc' thus works right out of the box:
{
"query": {
"match" : {
"fullTextVariables" : {
"query" : "abc"
}
}
}
}
Implementation-wise, fullTextVariables is nothing more than a shorthand for a variable extractor that copies that particular variable to the variableTypeAhead field that is part of the index mappings (more precise: it’s a field of every element of the variables array of a task, case, process or work element). That variableTypeAhead field is configured out-of-the-box to copy its value to the fullTextVariables field on the root of the json document.
Given the fact that configuring the fullTextVariables comes down to a variable extractor behind the scenes, this means that all of the usual callbacks for enhancing or changing data can be used. However, take in account that the variable extractor already has been applied when the callback is executed. This means that the value that will be copied to the fullTextVariables field will be in the special variableTypeAhead field. For example, suppose we want to always change the text value to uppercase for some reason, we can write the following enhancer:
public class ExampleEnhancer extends IndexedDataEnhancerAdapter {
@Override
public void enhanceHistoricVariableReindexData(HistoricVariableInstance historicVariableInstance, String id,
String type, String hierarchyType, ObjectNode data, IndexingManagerHelper indexingManagerHelper) {
String variableName = historicVariableInstance.getVariableName();
Object variableValue = historicVariableInstance.getValue();
if (variableName.equals("employeeName")) {
List<ObjectNode> variableObjectNodes = indexingManagerHelper.getVariableDataObjectNodes(data, "employeeName");
for (ObjectNode variableObjectNode : variableObjectNodes) {
variableObjectNode.put(IndexingJsonConstants.FIELD_VARIABLE_TYPE_AHEAD, variableValue.toString().toUpperCase());
}
}
}
}
Note that, to apply the change all the time we’d need to implement the create/update/reindex callbacks. Also note the getVariableDataObjectNodes method. It looks through all the gathered data and returns all matching json ObjectNodes that match the variable name. At the point of the callback the variable values have been duplicated for the self/parent/root use cases (see variable scoping for more details) thus (maybe counter-intuitively) more than one instance will typically be returned as shown in the example above.
Customize index settings
In some use cases, it could be that the default settings for a certain index or mapping needs to changed.
This can be achieved by providing a mapping extension which purpose is to change those settings (vs adding or changing properties of the mapping). All content below the settings property of the mapping extension is added to the index that gets created by using the referenced mapping. Please check the Elasticsearch documentation for all possible settings and options.
For example, the following mapping extension to the default tasks mapping will
- change the default index refresh interval to 100 seconds
- add a custom ngram filter (that then can be used in the properties of the mapping extension)
- add a custom tokenizer (that then can be used in the properties of the mapping extension)
{
"key": "my-task-mapping-extension",
"extends": "tasks",
"version": 1,
"properties": {
"name": {
"type": "text",
"analyzer": "customTokenizer"
}
},
"settings": {
"refresh_interval": "100s",
"analysis": {
"filter": {
"custom_filter": {
"type": "ngram",
"min_gram": "10",
"max_gram": "11"
}
},
"analyzer": {
"customTokenizer": {
"tokenizer": "whitespace"
}
}
}
}
}
Custom Aliases
Defining a custom query on the indexed data is often needed, for example for dashboards, reports, or other use cases. To define such queries, Flowable leverages the alias functionality of Elasticsearch. Such an alias is conceptually a 'view' on the data in an index that returns only matching data. Such an alias is always made in the context of an existing index. The reason for this is that all security and permissions checks for that particular index are added to make sure no data is returned that the user is not allowed to access.
noteIf you do need to expose full and unrestricted querying, it is always possible
to add in a custom REST controller class that exposes the com.flowable.indexing.SearchService functionality.
Such an alias is defined in a JSON configuration file found on the classpath at:
com/flowable/indexing/mapping-extension/custom.
Let us look at an example of such a custom alias:
{
"key": "custom-tasks",
"sourceIndex": "tasks",
"type": "alias",
"version": 1,
"customFilter": {
"bool": {
"must": [
{
"term": {
"scopeDefinitionKey": "myProcess"
}
},
{
"nested": {
"path": "variables",
"query": {
"bool": {
"must": [
{
"term": {
"variables.name": "accountNumber"
}
},
{
"match": {
"variables.numberValue": 123
}
}
]
}
}
}
}
]
}
}
}
The key, together with the version is important as they are used to determined if changes have happened to the definition. If so, the old alias is deleted and replaced by the new one. Type needs to be alias when defining an alias.
The customFilter is where the actual query is defined. The content of this field is a native Elasticsearch query. Anything that can be in Elasticsearch is possible. Note that the query is enhanced by Flowable code to include permission checks.
noteAs permission checks get added automatically to the query,
it is mandatory that the query is bool at the root of the query.
When the server is booted up with this alias configuration, the data can now be
fetched by doing a REST call to the platform-api/search/query-tasks/alias/custom-tasks
endpoint. In the example above, all tasks that are part of instances with a
definition that has a key 'myProcess' and where the 'accountNumber' variable
is equal to '123' are returned.
The following API’s are available, for each type respectively:
-
Tasks:
platform-api/search/query-tasks/alias/{aliasKey} -
Case instances:
platform-api/search/query-case-instances/alias/{aliasKey} -
Process instances:
platform-api/search/query-process-instances/alias/{aliasKey} -
Work instances:
platform-api/search/query-work-instances/alias/{aliasKey}
The response format of these REST API’s are consistent with those for the Form engine:
-
root variables are found under the root property
-
parent variables are found under the parent property
-
variables defined on the scope itself are properties directly on the response
Dynamic Queries
In the previous section, an alias was created that gives a view on the index. Aliases are a powerful mechanism as they are exposed to the highest level in Elasticsearch (meaning you can query or do anything with an alias that you can do with a regular index). However, an alias cannot utilize dynamic parameters (this is a limitation of Elasticsearch aliases). For this, Flowable allows the definition of dynamic queries.
A dynamic query definition is a JSON configuration file found in the classpath location
com/flowable/indexing/mapping-extension/custom. A dynamic query definition looks
similar to an alias definition:
{
"key": "custom-query-tasks",
"type": "query",
"sourceIndex": "tasks",
"version": 1,
"parameters": {
"accountNumber": "number",
"defaultValue": "1234"
},
"customFilter": {
"bool": {
"must": [
{
"term": {
"scopeDefinitionKey": "myProcess"
}
},
{
"nested": {
"path": "variables",
"query": {
"bool": {
"must": [
{
"term": {
"variables.name": "accountNumber"
}
},
{
"match": {
"variables.numberValue": "{accountNumber}"
}
}
]
}
}
}
}
]
}
}
}
The key, type, version and sourceIndex properties have the same functionality as they do an alias. Also, the customFilter looks similar to the customFilter of the alias definition but instead of a hardcoded accountNumber variable in the query, it is a dynamic value that is referenced using curly braces {accountNumber}. The parameters section above defines which parameters this query accepts, what the type is (which is needed to properly parse the parameters when coming through the REST API for example) and optionally a default value for the parameter (used when there is no explicitly value passed in the REST API call).
The valid parameter types are:
-
string: The value is passed to the query as-is. -
number: The value is passed as a quoted string (i.e., 55 → "55"). -
boolean: The value is passed as a quoted string (i.e., true → "true"). -
stringList: A comma separated list of values (i.e.,?myTerms=val1,val2).-
Each value in the list is quoted before it is passed to the query.
-
Example query usage with above:
{ terms: [ "{myTerms}" ] }is expanded into{terms: ["val1", "val2"]}(Note: The list ([]) for the query is declared in the query mapping).
-
-
simpleList: Is the same as thestringListabove except the values are passed as is (i.e., val1,val2 → [val1, val2`).
When the server is booted up with the alias configuration shown above,
the data is fetched by doing a REST call to the
/search/query-tasks/query/custom-query-tasks
endpoint. Continuing with the example, all tasks that are part of instances with a
definition that has a key 'myProcess' and where the 'accountNumber' variable is equal
to the provided value are returned. Now use cases that take in parameters from
a form field are possible:
-
/search/query-tasks/query/custom-query-tasks?accountNumber=123 -
/search/query-tasks/query/custom-query-tasks?accountNumber=9876554 -
…
The following API’s are available, for each type, respectively:
-
Tasks:
platform-api/search/query-tasks/query/{queryKey} -
Case instances:
platform-api/search/query-case-instances/query/{queryKey} -
Process instances:
platform-api/search/query-process-instances/query/{queryKey} -
Work instances:
platform-api/search/query-work-instances/query/{queryKey}
The response format is similar to the alias REST response.
Default Parameters
The following parameters are reserved keywords that are available when defining queries:
-
currentUserIdinjects the id of the currently logged-in user. -
currentGroupsinjects an array of the group keys for the current logged-in user. -
currentTenantIdinjects the current tenant id of the logged-in user. -
currentTimeinjects the current time as an ISO8601 formatted text string.
The following parameters are reserved keywords that are set when they are passed in the URL:
-
sort: The fields to sort on; this can be a comma-separated list. -
order: The sort order (ascordesc). -
start: The start of the requested page of data. The default is zero (0). -
size: The size of the page of data. The default is 20.
Custom Sorting
v3.2.1+By default, all fields in the index mapping that are sortable in
Elasticsearch (numbers, keywords, etc.)
can be passed as a parameter when calling the query REST endpoint,
passing in a value for the sort and order parameter.
For example (where example is the name of query):
-
/platform-api/search/query-tasks/query/example?sort=scopeDefinitionKey&order=asc -
/platform-api/search/query-tasks/query/example?sort=priority&order=asc
Multiple levels of sorting is also possible:
/platform-api/search/query-tasks/query/example?sort=scopeDefinitionKey,priority&order=asc,desc
Queries of a similar form are available for process, case, and work instances.
Often, there is also a need to sort on a variable value.
To do so, a sortParameters configuration needs to be added to the query definition.
For example:
{
"version": 1,
"name": "example1",
"type": "query",
"sourceIndex": "tasks",
"sortParameters": {
"customerName": {
"type": "text",
"variable": true
}
},
"customFilter" : {
"bool": {
"must": [
{"term": {"scopeDefinitionKey": "myDefinition"} }
]
}
}
}
Here, the customerName is a variable. The type is important to define
correctly in this definition.
Supported types are text, number, date, boolean, decimal.
The variable flag needs to be set to true.
noteThe type needs to be provided as it cannot be determined from the REST endpoint URL when getting the data.
The query can now be used through the following REST URL:
/platform-api/search/query-tasks/query/example1?sort=customerName&order=asc
Behind the scenes, Elasticsearch expands this definition into syntax that looks like:
"sort": [
{
"variables.textValueKeyword" : {
"order" : "asc",
"nested": {
"path": "variables",
"filter": {
"term" : { "variables.name" : "customerName" }
}
}
}
}
]
For a numeric variable, this it looks like:
"sortParameters": {
"customerAge": {
"type": "number",
"variable": true
}
}
And for a date variable:
"sortParameters": {
"customerBirthDate": {
"type": "date",
"variable": true
}
}
Multiple levels of sorting based on variable values are also possible:
"sortParameters": {
"companyName": {
"type": "text",
"variable": true
},
"companyAge": {
"type": "number",
"variable": true
}
}
Sorting can also be done using an extracted JSON value.
For example, given the following variable extractor in a custom mapping:
"variableExtractors": [
{
"filter": {
"name": "customer",
"scopeDefinitionKey": "myProcess"
},
"path": "/nestedField/companyName",
"to": "extractedCustomerName",
"type": "string"
}
]
The extractedCustomerName can now be used for sorting, in the query definition:
"sortParameters": {
"extractedCustomerName": {
"type": "text",
"variable": true
}
}
Which in turn can be used in the REST request:
/platform-api/search/query-tasks/query/testSortParams6?sort=extractedCustomerName&order=asc
Paging Queries
To fetch a page of data from the index, pass the start and size parameters:
For example: /platform-api/search/query-tasks/query/example?sort=scopeDefinitionKey,priority&order=asc,desc&start=10&size=50
Dynamic Queries with Templates
When the out-of-the-box query mechanisms are insufficient, it is possible to create a fully custom query using a Freemarker template.
Such a query looks as follows:
{
"version": 1,
"name": "queryWithTemplateExample",
"type": "query",
"sourceIndex": "process-instances",
"templateResource": "classpath:/com/flowable/test/index/mapping/template/query-process-instances.ftl"
}
This looks like a typical query, except there is only one field to reference the template that needs to be used.
The templateResource is a Spring resource reference. In this case, a template on the classpath is referenced.
Such a template can be anything that Elasticsearch supports. Since this is a Freemarker template, conditional blocks and replacements are possible. For example:
<#ftl output_format="JSON">
{
"from": 0,
"size": 20,
"query": {
"bool": {
"must": [
{"term": {"processDefinitionKey": "${key}"}}
]
}
},
<#if customSort == "sortVersionA">
"sort" : [
{
"variables.textValueKeyword" : {
"order" : "asc",
"nested": {
"path": "variables",
"filter": {
"term" : { "variables.name" : "customerName" }
}
}
}
}
]
</#if>
<#if customSort == "sortVersionB">
"sort" : [
{
"variables.numberValue" : {
"order" : "desc",
"nested": {
"path": "variables",
"filter": {
"term" : { "variables.name" : "customerAge" }
}
}
}
}
]
</#if>
}
In this example, the key parameter is used to filter the process definition
and two types of sort are possible using the customSort parameter.
The REST endpoint to call these queries is the same as for normal queries. For example, this template could be executed using:
-
platform-api/search/query-process-instances/query/queryWithTemplateExample?key=myProcess&customSort=sortVersionA -
or
platform-api/search/query-process-instances/query/queryWithTemplateExample?key=anotherProcess&customSort=sortVersionB -
…
 warning
warningWhen using a template, no automatic permission checks are applied (as is the case for normal queries).
This means that permissions need to be added by the creator of the template. This can for example be done using the query default parameters
currentUserId, currentGroups and currentTenantId with fields identityLinks and tenantId.
Filtering out search results
Sometimes it is needed to remove certain search results that would be returned by the Flowable Search REST APIs.
In order to achieve this an implementation of ResultFilter<T> is needed.
Implementing this interface will make sure that the infinite scrolling in data tables works correctly when using the Search REST APIs.
The generic parameter <T> can be one of:
ProcessInstanceSearchRepresentation- for filtering out process instancesCaseInstanceSearchRepresentation- for filtering out cases instancesWorkInstanceSearchRepresentation- for filtering out root process / cases instancesTaskSearchRepresentation- for filtering out tasks.
An example implementation for filtering out all tasks that contain hide in their name looks like:
public class TaskSearchRepresentationResultFilter implements ResultFilter<TaskSearchRepresentation> {
@Override
public boolean accepts(TaskSearchRepresentation response) {
if (StringUtils.containsIgnoreCase(response.getName(), "hide")) {
return false;
}
return true;
}
}
In order for this result filter to be used we need to register it in the Spring context via:
@Configuration
public class CustomConfiguration {
@Bean
public TaskSearchRepresentationResultFilter taskSearchRepresentationResultFilter() {
return new TaskSearchRepresentationResultFilter();
}
}
When using such a ResultFilter Flowable will keep requesting data from ElasticSearch until the requested page size is filled out
Customizing the Requests to Elasticsearch
v3.11.0+Flowable currently uses the Elasticsearch Low Level Rest Client to communicated with Elasticsearch.
When sending the requests the default Request Options are used.
The default allowed response size set by Elasticsearch is 100 MB.
If for whatever reason your responses have more data, and you are receiving exceptions containing "entity content is too long [xxx] for the configured for the configured buffer limit [xxx]"
you can provide your own bean of RequestOptions that will be used by Flowable when communicating with Elasticsearch.
e.g. In order to increase the allowed response size you can do something like:
@Bean
public RequestOptions customRequestOptions() {
int bufferLimit = 200 * 1024 * 1024; // 200MB
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
builder.setHttpAsyncResponseConsumerFactory(
new HttpAsyncResponseConsumerFactory.HeapBufferedResponseConsumerFactory(bufferLimit)
);
builder.build();
}
Or you can provide your own implementation of the HttpAsyncResponseConsumerFactory.
noteThis is available from v3.11.0+. This is a third party API and Flowable cannot guarantee backwards compatibility in it.
Low-Level Bulk Request Interceptor
warningThe Low-Level Bulk Request Interceptor is an experimental interface and the APIs may change.
All indexing in Flowable is handled by the async executor which executes history jobs that contain the data that needs to be indexed. Data from the same database transaction are grouped in one bulk request to Elasticsearch for performance reasons.
It is possible to add a custom interceptor, both before and after the execution of a bulk index request. This interceptor exists on the lowest possible level of the indexing logic and can be used to make changes to the request just before it is sent to Elasticsearch or right after the response comes back from Elasticsearch. This interceptor should only be used when no other higher-level mechanism exists.
To define a new interceptor, add a Spring bean implementing the
com.flowable.indexing.job.history.asyncBulkIndexRequestInterceptor interface to
your Spring @Configuration class. Multiple beans implementing this interface are possible.
Example:
public class MyInterceptor implements BulkIndexRequestInterceptor {
@Override
public void beforeRequestAddToBulkIndexingSession(String index, IndexedDataObject indexedDataObject, ObjectNode originalData) {
}
@Override
public void beforeRequestExecution(BulkRequest bulkRequest) {
}
@Override
public void afterRequestExecution(BulkRequest bulkRequest, BulkResponse bulkResponse) {
}
}
Reindexing
Reindexing may be required when:
-
Elasticsearch does not have strong transactional guarantees like a relational database. Although the chance is small, a hardware or network failure could corrupt the indexes which would mandate a reindex. In that case, the data from the relational database is used to rebuild the indexes.
-
When a Flowable product upgrade adds a new type of data or data that was not previously indexed, a reindex might be needed (this should not frequently happen, as Elasticsearch can cope with many types of changes here). Changes that require reindexing are documented in the upgrade notes for a release.
Reindexing is rebuilding the index for the particular data from scratch, based on the data in the relational database. Reindexing is triggered through Flowable Control or the REST API by an administrator and is executed asynchronously in the background. The reason for this is that it would not be suitable to keep an HTTP thread blocked for so long while reindexing. For example, the server could deem the thread starved and kill it, and load balancers and proxies often terminate connections that stay open for too long.
Reindexing uses the following algorithm:
-
A new index is created with a unique name.
-
Data from the database tables are fetched in pages (multiple rows at once) and in parallel.
-
Each page is processed, and the data from the tables is transformed into a job for the Flowable async executor. This action too, is parallelized.
-
The async history executor now picks up the job and transforms the job into a bulk index request for Elasticsearch.
-
Once Elasticsearch acknowledges the indexation, the job is deleted. In case some parts of the bulk index failed, a new job with the failing parts is created to be picked up and retried later.
-
When all jobs have been processed, the alias is swapped to the index created in step 1.
-
A new reindexing is now planned to catch any data that has been added, updated, or removed since the reindexing was triggered. This has no impact on users, as it runs asynchronously in the background, and the index was already swapped in step 6.
In Flowable Control, a reindex can be triggered from the Indexes entry on the left-hand menu and selecting an index.
Once selected, click the Reindex button in the header of the page.
In the log of Flowable Work, you'll now see the following lines appear (from version 3.14.0+), which match steps 1-7 of the description above.
com.flowable.indexing.ReindexManagerImpl : Reindex of index process-instances started.
com.flowable.indexing.ReindexManagerImpl : Waiting for the completion of 1 asynchronous index jobs
com.flowable.indexing.ReindexManagerImpl : Swapping alias process-instances from process-instances-20230725-0940-37-34837281 to process-instances-20230725-0940-58-34858884
com.flowable.indexing.ReindexManagerImpl : Alias process-instances swapped from process-instances-20230725-0940-37-34837281 to process-instances-20230725-0940-58-34858884
com.flowable.indexing.ReindexManagerImpl : Updating index metadata for index process-instances-20230725-0940-58-34858884, metadata: {"version":9,"indexMappingName":"process-instances"}
com.flowable.indexing.ReindexManagerImpl : Finished updating index metadata for index process-instances-20230725-0940-58-34858884
com.flowable.indexing.ReindexManagerImpl : Reloading indices
com.flowable.indexing.ReindexManagerImpl : Reindexing of index process-instances completed part one and swapped alias. Triggering another reindex in order to catch any data that has fallen through the small window when swapping the alias. The second part is only going to create the history jobs. It won't wait for them to complete.
com.flowable.indexing.ReindexManagerImpl : Part two of reindexing of index process-instances done. Created history jobs. To validate that there is no reindexing anymore check that there are no more history jobs.
As indicated by the last log line, the reindexing is only fully completed when all jobs have been processed. There's no logging for the completion of all indexing jobs, as there can be any amount of indexing jobs that are handled in any random order.
Additionally, dedicated REST endpoints for each type exist for reindexing, making it possible to select which index needs to be rebuilt. This reindexing is done by executing an HTTP POST request using administrator credentials.
-
Work instances:
platform-api/work/reindex -
Case instances:
platform-api/case-instances/reindex -
Process instances:
platform-api/process-instances/reindex -
Tasks:
platform-api/tasks/reindex -
Activities:
platform-api/activities/reindex -
Plan items:
platform-api/plan-items/reindex -
Conversations:
engage-api/conversations/reindex(Engage only) -
Users:
idm-api/users/reindex -
Content items:
platform-api/content-items/reindex
Reindexing is an expensive operation, especially with lots of data. For a production system, the recommendation is always to have a backup using the snapshot mechanism of Elasticsearch.
In the case of a failure, a recent snapshot can be used to restore the system quickly. However, data that was created or changed since the last snapshot is not in that snapshot. The data still resides in the relational database. When now triggering a reindex, the index is updated in the background asynchronously, and the system eventually recovers automatically. This way, the users can continue working with the system, albeit in a state where some data is missing or incorrect.
Synchronous vs Asynchronous History
v3.14.0+The usage of asynchronous history has been deprecated in 3.14.0 and it will be removed in a future version. It is advised to use synchronous history.
There is an important difference regarding indexing whether the system is configured to use synchronous or asynchronous history.
In general, when users (or automated systems) interact with the API’s of Flowable this means that processes, cases, rules, forms, etc. are deployed, started, completed, etc. This generates history data (besides the runtime data) that gets indexed in Elasticsearch. The historical data is stored in various history tables by each Flowable engine.
This history data can be produced either synchronous or asynchronous, by setting the following property:
flowable.async-history.enable-async-relational-history=false
This option is available from version 3.8.0. The default is
false(i.e. synchronous).In prior versions (< 3.8.0) the default was
asynchronousandsynchronouswas not available.
The difference between the two is the following:
- When using synchronous history, the historical database tables are populated during the runtime database transactions. This means that when a database transaction commits, both the runtime and historical data is fully in sync (hence the usage of the terminology synchronous). This also means that the historical queries and data are guaranteed to work and be there in the next API call, which can be a benefit for human-driven scenarios.
- When using asynchronous history, the engine gathers historical information in one JSON document and inserts that (in one table row) at the end of the transaction. Afterwards - and asynchronously - the async history executor component of Flowable picks this up and unravels all the information into the various table rows. For high-throughput scenarios (especially with lots of automated system orchestration) this can benefit the overall throughput of the system. However, the downside is that the historical data will follow typically with a slight delay.
In both options, the data meant for indexing is correct and equivalent to the database (taking into account the eventual consistency of Elasticsearch).
And in both options, the indexing in Elasticsearch happens asynchronously by the Flowable async executor. This asynchronous indexing behavior, when using asynchronous history, will run typically concurrent with the processing of the history data.
Let's have a look at what this difference in history handling means for indexing.
Synchronous History Indexing
When running with synchronous history enabled, the indexing logic becomes simple: the indexing job only needs to contain the entity ids and types that were updated. The asynchronous indexing job logic can always fetch the latest correct state from the database (as it was committed during the runtime transaction) and index that data. In fact, that logic is very similar to the reindexing concepts.
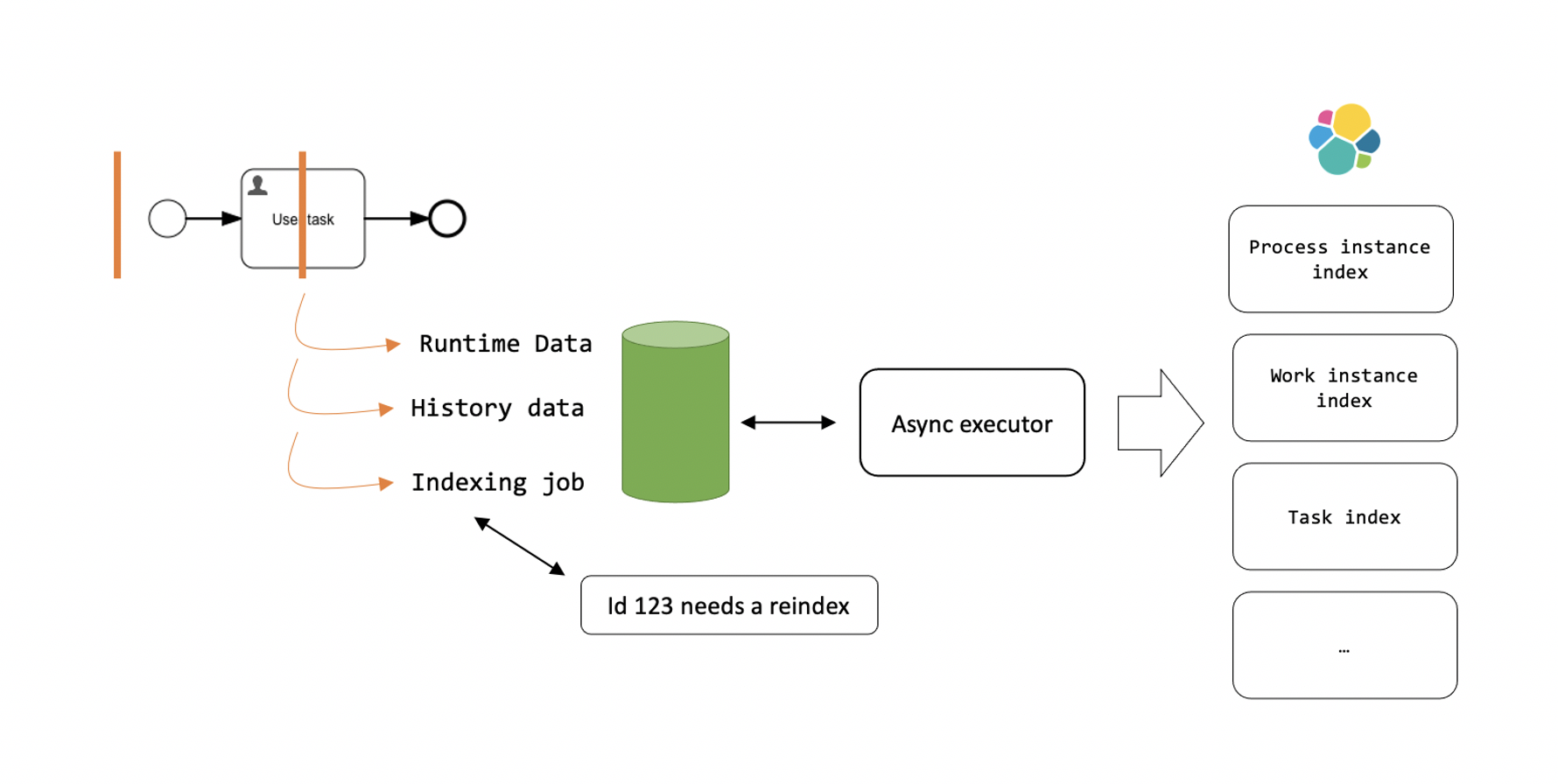
Asynchronous History Indexing
When running with asynchronous history however, the indexing job cannot depend on the data in the history data tables to be there as the asynchronous history job might not yet have been processed. As such, this means that the indexing job needs to contains the delta between the old and new state to correctly update (and sometimes more data, to be idempotent).
The mechanism used behind the scenes when setting flowable.async-history.enable-async-relational-history to true is used by the Flowable Async History Executor, which is a component found in the Flowable open source engines that stores data in dedicated database tables:
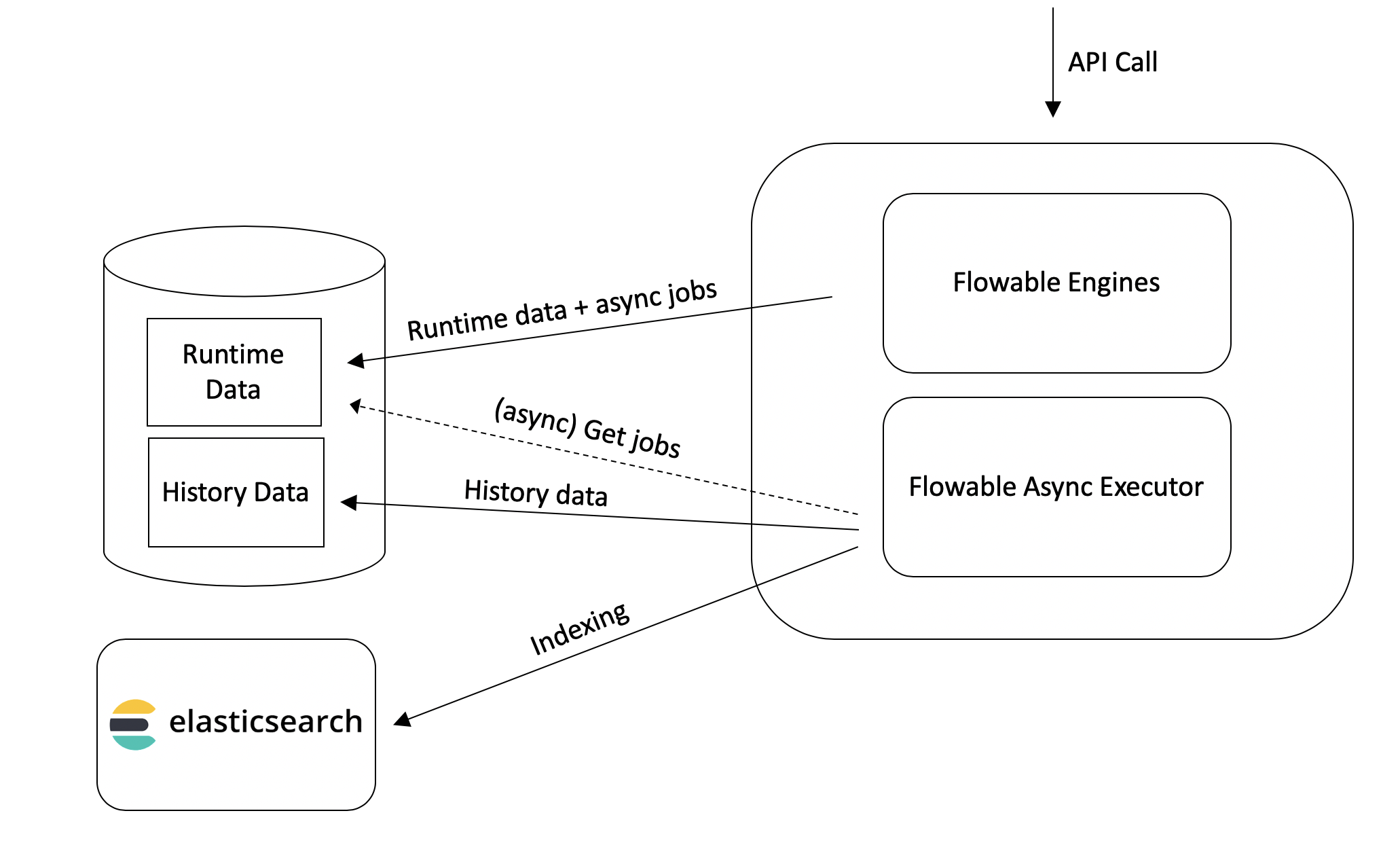
For use cases that require primarily automated service orchestrations, this is a good choice as there is typically no need for the data to be ready in a next screen for the user.
noteIn Flowable Control, the history jobs can be seen in the 'Job Execution' dashboard. These history jobs will be the combination of both asynchronous history and indexing jobs. In the synchronous history counterpart, this chart will only show the indexing jobs.