Multi-agent Orchestration in CMMN and BPMN
Flowable supports integrating a wide array of AI services into case and process models. These services can range from simple, single-invocation interactions, such as a one-shot call to a large language model (LLM), to more advanced, long-lived agents that participate in multiple steps and decisions within the same case or process.
Agent? Agentic?
In the context of AI, an agent refers to a system or component capable of performing actions autonomously based on goals, inputs, and context.
Agentic behavior implies that the AI is not merely reactive, but can make decisions, initiate actions, and maintain state across interactions. In Flowable, agents can function over time, respond to evolving case data, and assist in decision-making or task execution in a consistent, governed way.
Regardless of complexity, all AI integrations in Flowable are abstracted using an agent model. This model provides a unified, standardized way to define and interact with AI services, regardless of whether the underlying system is stateless or stateful, simple or complex.
Agents are invoked in process and case models using an agent task, a dedicated modeling task available in both BPMN and CMMN. These tasks follow the notational standards of their respective specifications, ensuring consistency and compatibility with existing modeling practices. This way, the use of AI services in existing or new business solutions can be controlled to make sure data is only sent to relevant places, the context being built up is kept in check and all invocations are audited.
It’s important to note that Flowable remains vendor-agnostic when it comes to agent providers and underlying models. The choice of which AI service, agent architecture, or model to use is left to the modeler defining the agent model and its usage within case or process models. This flexibility allows for a wide range of integration scenarios, including multi-agent setups, where different agents collaborate, and multi-model configurations, where various foundational models are used based on the task at hand. This open approach ensures that organizations can tailor AI orchestration to their specific needs, without being locked into a particular vendor or technology stack.
With the orchestration features of CMMN and BPMN and AI agent tasks where relevant, it's already possible to tackle a wide array of automation problems. However, it's also possible to define an orchestrator agent for a CMMN case model, which adds an over-arching agent that assists with managing the case context, suggesting next steps or taking decisions autonomously.
When should I use an Agent Task?
As is often the case in software engineering, the answer is: it depends. Flowable is used across a wide range of industries and use cases, so there is no one-size-fits-all recommendation.
That said, a useful guiding principle is to not overuse AI where traditional approaches are more suitable. Case and process management, along with established software engineering practices, provide a solid foundation for building reliable, scalable, and maintainable systems. Tasks such as executing well-defined steps, handling errors, persisting data, or coordinating service calls are areas where conventional modeling patterns are effective and proven.
Agent tasks, and AI in general, are most valuable in situations where unpredictability or unstructured input is involved. Use them for the "hard parts": interpreting intent, analyzing or summarizing content, generating text, or making suggestions where traditional logic would become overly complex or brittle.
Patterns
Patterns are a key part of any robust software solution. They provide (amongst others) consistency, reusability, maintainability and interoperability.
In the AI community, much has been written about patterns for building AI-enabled systems. However, many of these patterns are well-known in the BPMN and CMMN space for years. Below are several common patterns you might encounter in the AI literature, and how they directly map to standard process and case modeling constructs:
- Prompt chaining involves connecting multiple AI steps where the output of one becomes the input of the next. In BPMN or CMMN, this is simply modeled by sequential steps that invoke agent tasks one after the other, possibly with exclusive gateways in between to control flow.
- Human-in-the-loop refers to involving a human to review or approve AI-generated decisions. This is a common and natural pattern in both BPMN and CMMN. For example, boundary events can escalate a task if a condition is met, or a user task can be guarded by an entry sentry to ensure it only becomes active under certain conditions.
- Routing is about directing a flow based on decision logic or AI output. In BPMN, this is achieved using gateways; in CMMN, sentries provide this control. Both allow for data-driven routing in a standardized, visual way.
- Parallelization means running multiple tasks at the same time. CMMN naturally supports concurrent execution: dropping tasks on the canvas results in parallel behavior by default. BPMN allows for explicit parallelism using parallel or inclusive gateways.
- Memory refers to the ability to retain and use contextual data across steps. In Flowable, this aligns with the context built up during case or process execution. The state of the instance is held, for example, in variables, which effectively represent a condensed form of memory used by both the orchestration logic and any AI services.
- Service orchestration involves automatically calling external systems or services based on logic. While direct invocation via an agent tool is technically possible, in enterprise environments it is more reliable to model this explicitly in BPMN or CMMN. This ensures calls are auditable, repeatable, and guarded within a controlled transaction context.
- Evaluator–optimizer refers to a pattern where one component evaluates results and another refines or improves the outcome based on that evaluation. This can be implemented in a case or process model with a set of agent tasks passing data iteratively. Alternatively, when using an orchestrator agent, this can be handled implicitly using the AI Activation feature, which evaluates when and how to initiate steps dynamically.
Enterprise Features
While there are many tools and frameworks available for invoking AI services, they often focus on tying things together in flows. However, in an enterprise context, simply invoking an AI model is not enough. What’s needed is orchestration: the ability to systematically coordinate AI capabilities across processes, cases, systems, and human interactions, all while maintaining control, visibility, and consistency.
This is where an automation platform like Flowable comes in, which comes with all the enterprise requirements built-in:
- Versioning: Every model, whether a case, process, or agent, is versioned. This enables safe evolutions of automation logic and AI integrations over time, while preserving backward compatibility and traceability.
- Auditing: Executions and AI invocations can be fully logged, providing a reliable audit trail to track what decisions were made, when, and why. This is especially important for regulated or business-critical scenarios.
- Permissioning: Access to AI capabilities, models, and results can be controlled using a fine-grained permission model, integrated with enterprise identity and access management systems.
- Performance & Scalability: Built for high throughput and horizontal scaling, ensuring that AI-powered automation runs reliably under demanding conditions and can scale with business needs.
- Context Management: Long-running processes and cases maintain their evolving state over time, allowing AI invocations to operate with the right context and only the relevant information at every step.
- Observability: Logs, metrics, and audit events provide insight into AI behavior and system performance, supporting monitoring, troubleshooting, and optimization in production environments.
- Governance: Support for lifecycle management, change control, model approvals, and structured deployment flows ensures compliance with organizational governance policies.
- Privacy: Data passed to AI services can be filtered and controlled, reducing the risk of leaking sensitive or private data and helping meet privacy and compliance requirements.
- Unified API Design: A consistent API layer allows services, AI or otherwise, to be invoked and exposed in a predictable, maintainable, and interoperable way.
Building Blocks
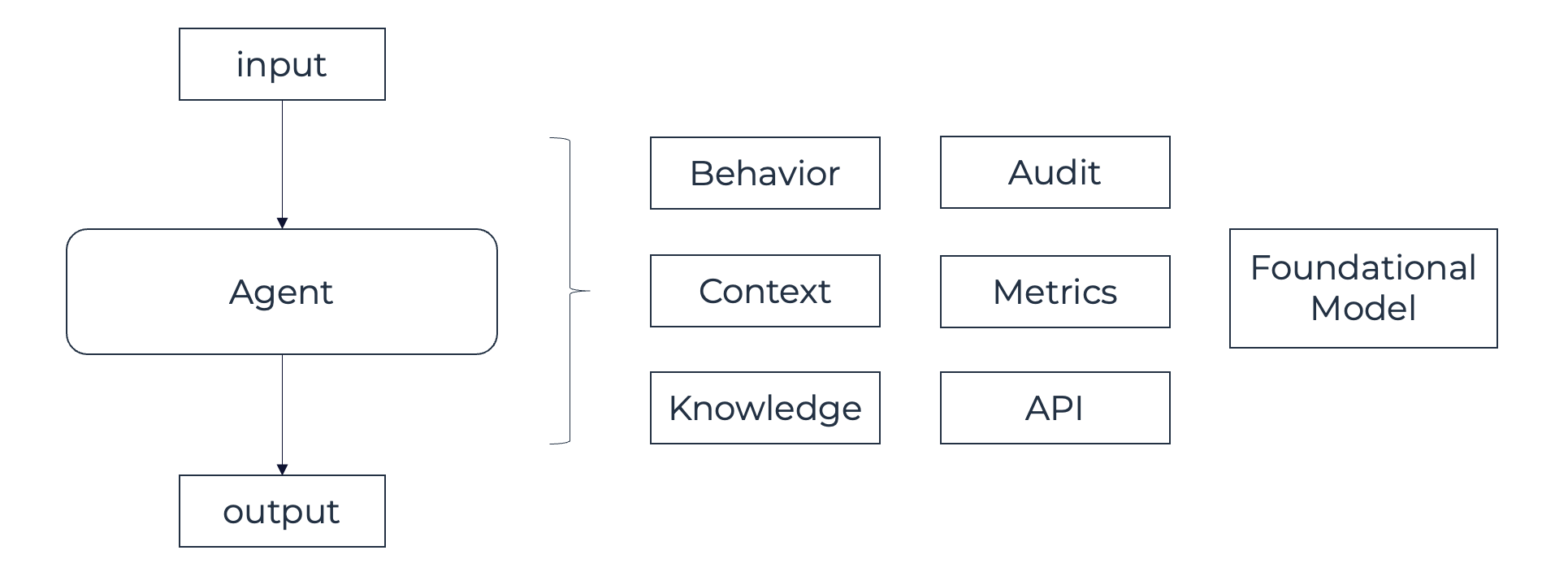
From a high-level orchestration perspective, invoking an agent can appear similar to invoking a service. Both involve calling an external component and handling its response within the flow of a process or case. However, while there are clear similarities, there are also important differences that justify treating them as distinct building blocks.
Agents are not just service endpoints: they can maintain context, make decisions and are typically driven by prompts. Their behavior can evolve based on prior interactions, case state, or knowledge bases. And when it comes to the orchestrator agent, it even interacts across multiple points in a case.
Let's have a look at the high-level building blocks of an agent model:
Input & output
An agent model defines a set of input and output parameters that configure how data is exchanged during its execution. These parameters can be untyped, supporting flexible, chat-like interactions, or be explicitly typed and structured. For use within a process or case models, structured parameters are generally recommended. They help ensure that each agent invocation behaves consistently and produces predictable results across different instances.
When passing data into an agent via its input parameters, it's important to include only the information that is strictly necessary for the agent to perform its task. While it may be tempting to provide a large set of runtime variables, doing so can introduce noise, reduce clarity, and increase the risk of unintentionally exposing sensitive or private data to external systems.
Behavior
The behavior of an agent defines how it processes input and produces output. This behavior depends on the type of agent being used:
- For external agents, the logic and functionality are managed outside of Flowable. In this case, Flowable acts as the orchestrator, invoking the external system based on the agent model’s configuration and passing along any required input parameters.
- For built-in or prompt-based agents, the behavior is defined within Flowable itself through the use of configurable prompts. These include:
- A system prompt, which provides context or instructions to guide the AI’s behavior consistently across invocations.
- A user prompt, which typically contains dynamic content derived from the current case or process context and forms the actual request made to the agent.
Prompt?
A prompt is a piece of text that tells an AI service what you want it to do. It acts as an instruction or request and guides the AI’s behavior and response. Think of it as giving directions to a very capable assistant that understands natural language.
In Flowable, prompts are used to configure how an agent should behave when it is invoked. Prompts can be:
System Prompt: This sets the overall behavior or personality of the AI. It stays the same across multiple interactions. Examples:
"You are a helpful and concise business analyst."
"Respond in formal language and only with bullet points."
"Act as a legal assistant reviewing contract clauses for risk."
User Prompt: This is the actual instruction or request given during a specific interaction. It can include dynamic data from the process or case. Examples:
"Summarize the following meeting notes: $\{meetingSummary}"
"Given the order details, create a friendly shipping confirmation message."
"Analyze the complaint and suggest a next best action: $\{complaintText}"
Prompts are central to working with large language models. By adjusting the wording and structure of prompts, you can control the tone, depth, and type of response the AI provides. Well-crafted prompts make AI agents more predictable, useful, and aligned with your business needs.
Context
Context refers to the evolving state of data and decisions during the execution of a case or process instance. This context is built up implicitly as the orchestration progresses. For example, in a KYC (Know Your Customer) process, the context at the start of the case is limited, perhaps just a name and identifier. As the process advances, more data is collected: identification documents, risk scores, verification results, and so on. By the midpoint, the context has changed significantly, reflecting a more complete picture of the customer and the onboarding status.
Context plays an important role in AI integration, especially in AI-driven orchestration. The quality and relevance of the information available at each point directly impact the usefulness and accuracy of AI decisions. Whether it's suggesting the next best step, triggering an intent, or interpreting user input, AI depends on having access to the right context at the right time.
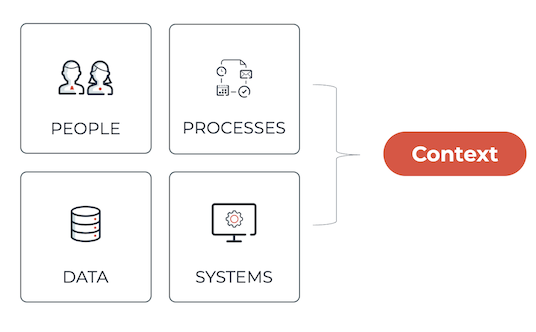
There is no single configuration block labeled "context" in an agent model. Instead, the context emerges from the case or process design itself: through user tasks, service calls, variables, and conditional logic. When agent tasks are introduced into the model, they operate on a snapshot of this context: the specific data passed into the agent becomes the working context for that invocation.
This is why the design of context, i.e. what data is available at which point, and how it evolves, is critical. In fact, context engineering is arguably more important than prompt engineering. While prompt engineering focuses on how to ask the AI for the right thing, context engineering ensures the AI has the right information to work with in the first place. It encourages thinking in terms of orchestration lifespans: what data is available at each stage, and how that data shapes AI behavior.
Knowledge
Certain agent model types have the capability to reference a knowledge base, applying the Retrieval Augmented Generation (RAG) pattern to the prompts.
Audit & Metrics
When using agent models in Flowable, configuration options control how much audit information and execution metrics are recorded. Capturing this data is essential when integrating AI services, particularly in enterprise environments where traceability and accountability are required.
In Flowable, this data is stored in so-called agent exchanges. These exchange records provide a historical view of agent interactions, including the input and output data, the prompts used, and the resulting decisions or suggestions. This allows teams to review and validate how and why a particular response was generated, or why a specific path in a case or process was taken.
The agent exchanges can be found in Flowable Control or accessed through REST- or Java APIs.
API
In an agent-driven architecture, it is often important to expose agents via APIs so they can be accessed by other systems (or by other agents) as part of a broader orchestration. Flowable provides configuration options to control how and when agent models are exposed in this way.
Foundational Model
Defines the underlying large language model or AI service used by an agent. For agent models managed within Flowable, the foundational model can be selected and configured through the model settings. This allows precise control over which provider, version, or model variant is used (e.g., GPT-4, Claude, etc.), depending on the desired capabilities and constraints.
For external agents, the foundational model is not configured within Flowable. In those cases, the behavior, model choice, and hosting details are defined and managed externally.
Foundational Models?
Different foundational AI models exist because they are designed and trained with varying goals, strengths, and trade-offs. Much like how people have different skills and areas of expertise, AI models specialize in certain types of tasks or behaviors.
Some models are optimized for generating fluent, natural language, making them well-suited for tasks like writing or conversation. Others may focus on precision and accuracy, which is important for tasks requiring detailed analysis or strict adherence to instructions. Performance characteristics such as speed, cost, and the ability to handle long or complex inputs also vary between models.
Additionally, the underlying training data, architecture, and tuning approaches differ across models, influencing how they interpret language, respond to prompts, and manage context. These differences affect the quality, reliability, and suitability of a model for specific applications.
Example
See the reference documentation for an example on building your first utility agent model.